The Developer's Guide to Speech Recognition in Python
Jose Nicholas Francisco

Introduction
“Hey, Alexa, is speech recognition really important?”
The short answer? Yes.
If you’ve been paying attention to hardware and software trends, you’ll notice speech recognition, audio analysis, and speech creation have become top of mind for modern developers. As we move towards a world full of VR and ambient computing, learning how to use these APIs is going to be an important part of new architectures. In this article, we’ll talk most about speech recognition APIs, but you will want to use a number of tools to first edit, filter, and improve audio.
But first, let's go over some of the basics.
What is Speech Recognition?
Speech recognition (a.k.a. speech-to-text) converts audio data into data formats that data scientists use to get actionable insights for business, industry, and academia. It is a method to change unstructured data (data not organized in a pre-defined manner) into structured data (organized, machine-readable, and searchable). Other names of speech recognition are speech-to-text (STT), computer speech recognition, or automatic speech recognition (ASR).
Some have also called it voice recognition but that term is defined differently. Voice recognition is defined as identifying a specific person from their voice patterns. Voice recognition is a feature of speech recognition. You can use speech recognition solutions in combination with artificial intelligence to identify a specific speaker and tie that voice pattern to a name.
Why is Speech Recognition Important?
When you look at all the data being generated in the world, only 10% of that data is structured data. That means 90% of the world’s data is unstructured; unsearchable and unorganized, not yet being used for business insights. In addition, unstructured data is forecasted to increase by 60% per year. When you think about it, many organizations are making important decisions on only 10% of the data.
Most of this unstructured data is voice or video data that needs to be changed into machine-readable data to be used for decision-making. This is where ASR comes in and why it is so important.
The History of Speech Recognition
The history of speech recognition can be traced to technologies first developed in the 1950 and 1960s, when researchers made hard-wired (vacuum tubes, resistors, transistors and solder) systems that could recognize individual words, not sentences or phrases. That technology, as you might imagine, is essentially obsolete. The first known ASR was developed by Bell Labs and used a program called Audrey, which could transcribe simple numbers. The next breakthrough did not occur until mid-1970 when researchers started using Hidden Markov Models (HMM). HMM uses probability functions to determine the correct words to transcribe.
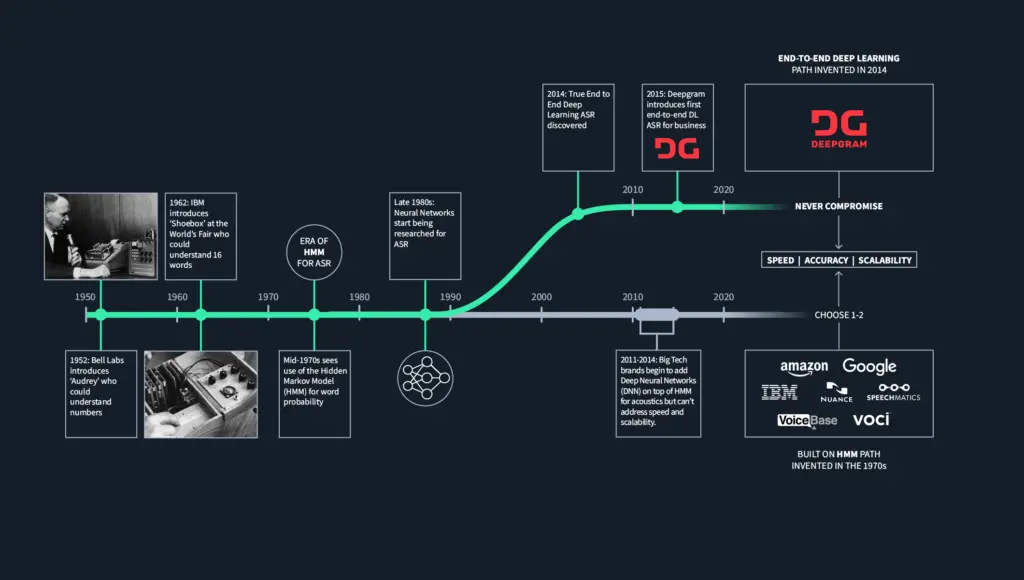
Figure 1: History of Speech Recognition and Hidden Markov Models
Figure 1: History of Speech Recognition and Hidden Markov Models
Choosing a Speech Recognition Package
When looking for a speech-to-text solution, you should always first see how you can use the many features available to you. Some of the solutions we’ll mention aren’t exactly STT systems but instead help improve audio so that true STT systems can process it more efficiently. Ultimately, you’re going to be using a few solutions per application, so don’t be afraid to mix and match.
The most popular Python speech and audio analysis tools are SpeechRecognition, PyAudio, and Librosa. PyAudio is a library that provides access to audio devices and allows developers to record and play audio. Librosa is a library that provides a wide range of audio analysis tools, such as pitch detection, beat tracking, and audio segmentation. We’ll explore each individually.
These tools are invaluable for a variety of applications, such as speech recognition, audio processing, and music analysis. Speech recognition can be used to create voice-controlled applications, such as virtual assistants. Audio processing can be used to create sound effects or to improve the quality of audio recordings. Music analysis can be used to create music recommendation systems or to detect musical patterns. With these tools, developers can create powerful and innovative solutions that can be used in a variety of applications.
What You Need From an STT Solution
When it comes to Speech-to-Text APIs, there are a variety of features that can be beneficial depending on your use case.
Accuracy is the most important factor, and a minimum of 80% accuracy should be expected from every transcription. If your system is spitting out stuff that looks like the transcription of a bad AM radio station you might want to rethink your choice.
Along with this, we recommend having batch transcription capabilities so that you can process multiple files at once. Meanwhile real-time streaming is necessary for applications that require immediate responses (with minimal latency). More and more meeting apps, for example, are adding active transcription, a feature that was akin to sci-fi a few years ago.
Multi-language support is important for those who need to handle multiple dialects, and automatic punctuation and capitalization can be helpful for surfacing transcripts publicly. Both of these are turning many products into global successes including popular tools and social media apps.
Profanity filtering or redaction is necessary for community moderation, and topic detection can be useful for understanding audio content. Custom vocabulary and keyword boosting can help improve accuracy, and tailored models can be used for specific needs. For example, if a product brand name is not a dictionary word, it’s still possible to recognize that term with additional training.
Finally, anything you use should accept multiple audio formats (MP3, WAV, M4A, etc) to save time and money.
STT in the Wild
What are some of the most common applications of these APIs? Here are a few examples:
Smart Assistants - Popular virtual assistants like Siri and Alexa use STT to convert spoken commands into text and then act on them. These systems can be repurposed to add voice to nearly anything.
Conversational AI - Voicebots allow humans to communicate with AI in real time by first converting speech into text. This is helpful when connecting users via call centers and toll-free lines. By taking in speech and converting it to actionable text you can quickly turn a disgruntled customer into a fan.
Contact and Call Centers - Contact centers can use STT to create transcripts of their calls, allowing them to better evaluate their agents, understand customer inquiries, and gain insight into their business.
Speech Analytics - Speech analytics is the process of analyzing spoken audio to extract insights such as sentiment analysis, talking speed, and frequency of non-word, uhhhh, utterances. This can be done not only in a call center, but also in other environments such as meetings or speeches. This technique is especially helpful when managing things like focus groups.
Accessibility - Transcribing spoken speech can greatly improve accessibility, for example by providing captions for lectures or creating badges that transcribe speech on the fly.
Exploring the APIs
SpeechRecognition
SpeechRecognition is a library that allows developers to integrate speech recognition into their applications easily. It supports several engines and APIs, including Google Speech Recognition, Google Cloud Speech API, Microsoft Bing Voice Recognition, and many more. It supports both Python 2 and Python 3, and can be used to transcribe audio files or recognize speech in real time. It also includes a variety of features such as text-to-speech and keyword spotting.
PyAudio
Pyaudio is a Python package that provides bindings for the PortAudio library. In other words, it allows Python programs to access the audio devices on a computer—such as microphones and speakers— so users may play and record audio. As a result PyAudio enables developers and data scientists to integrate complex functionalities in a simple, intuitive way. Functionalities such as speech recognition, audio playback, and audio recording. It is also used for creating audio applications like music players, audio editors, and sound synthesizers. Pyaudio is cross-platform.
Deepgram
Deepgram provides a Python package for its speech recognition APIs that use powerful deep learning models to recognize speech. It is designed to be easy to use and integrate into existing applications. Deepgram can be used to recognize speech in a variety of languages, including English, Spanish, French, German, and Chinese. It can also be used to recognize speech in noisy environments. Deepgram's deep learning models have been trained on millions of hours of audio data, enabling accurate speech recognition in a variety of contexts. Deepgram also offers an extensive range of features, such as automatic language detection, keyword spotting, and speaker identification.
You can also use Deepgram speech-to-text for live-stream recognition. To date, Deepgram has transcribed trillions of tokens over the course of eight millennia worth of audio!
Librosa
Librosa is a music and audio analysis tool. It provides the building blocks necessary to create music information retrieval systems and it has a wide range of features including the ability to load audio from disk, compute audio features on the fly, and display audio features in a visual format. It also provides tools for audio segmentation, beat tracking, and pitch tracking. One of the interesting Librosa features is the ability to remove foreground vocals from a song automatically which can then be passed onto STT systems.
Pysptk
Pysptk is a Python package for speech analysis, synthesis, audio feature extraction, and other speech-related tasks. It is based on the original Speech Signal Processing Toolkit (SPTK) library developed by the Nara Institute of Science and Technology (NAIST). Pysptk provides functions for speech processing, including pitch extraction, mel-frequency cepstral coefficients (MFCCs) extraction, linear predictive coding (LPC) analysis, and many other complex speech tools. It also includes implementations of signal processing algorithms along with helper functions for data loading and visualization.
Finally, Pysptk includes a set of tools for speech synthesis, including a working vocoder and a speech synthesizer. Think of it as one of the more academic but powerful packages on our list.
Parselmouth
Parselmouth is a package for working with audio files as well as simple speech analysis using the Praat platform. The Python package provides a set of functions for reading, writing, and manipulating audio files in the Praat format. It also provides a set of functions for analyzing audio files including calculating pitch, intensity, and formants. Additionally, Praat can be used to create and manipulate audio visualizations and create sound frequency graphs. Note: The latest version of Parselmouth requires Python 3.
Audacity
This one isn’t really a Python framework but it is an open-source tool that you can use by calling os.system(). We like to use Audacity to record live audio, record playback, and covert digital recordings among various formats including WAV, AIFF, FLAC, and MP3.
Audacity can also change the speed, pitch, or tempo of a recording and even remove noise from audio files. Finally, you can add simple effects, including echoes and phasers.
Although there are few direct solutions for working with Audacity programmatically, Vinyl2Digital might be a useful tool if you’re looking for a basic Python interface.
Speechbrain
Speechbrain is an open-source Python library for building speech processing systems. It provides a unified framework for building end-to-end speech processing pipelines, from data acquisition to model training and inference. It is designed to be modular and extensible, allowing users to easily customize and extend existing components or add new ones. It also provides a set of pre-trained models and datasets for speech recognition, speech synthesis, and other tasks. Speechbrain is built on top of PyTorch and is compatible with both CPU and GPU hardware.
Torchaudio
TorchAudio is a python package that provides a set of tools for audio processing. It is built on top of PyTorch, a popular deep learning framework, and provides a high-level, fully abstracted API for audio processing. It provides a wide range of features that are especially useful for machine learning. These features include audio loading, signal processing, and feature extraction. It even provides a set of datasets for audio processing tasks.
What Should You Use?
All of the Python libraries featured above are decent options. The right choice for your project depends on your needs today, as well as anticipating your future needs. For example, you may think you don’t need automatic language detection today, but what if your application scales up and may need to accommodate speakers of multiple languages? It’s probably a good move to go with the most capable, flexible library available. Future-proofing your tech stack is always the prudent move.
If you think Deepgram is the right choice for you and your project, sign up for a free Deepgram Console account and get started with our API and Python SDK. If you have larger or more specialized needs, contact our sales team.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .