Chain-of-Thought Prompting: Helping LLMs Learn by Example
Brad Nikkel

Because the questions we ask Large Language Models (LLMs) heavily influence their outputs, “prompt engineering” is a key part of getting LLMs to do what we want them to do. This entails testing how close different methods of prompting LLMs (i.e., asking them questions) get us to our desired LLM responses.
It seems that conversing with a chatbot ought to be relatively straightforward. But it turns out that some communication strategies elicit quantifiably better results than others, similar to conversing with your fellow humans. When you, for example, ask any sufficiently large LLM “What’s the capital of Iowa?”, it’ll most likely correctly reply, “Des Moines”.
This ask-one-question-get-one-answer chatbot interaction is called input-output prompting. It’s about as basic as it gets.
Transcending Input-Output Prompts
Most of our meaty, meaningful conversations—ones that help us arrive at some insight or explain some complex topic—involve more than simple answers to simple questions. If, for example, we toss a tougher question like “How could Iowa resurrect its rural areas that are suffering economic hardship and population decline?” at our chatbot of choice, we aren’t likely to get much beyond a generic response—unless we slice the task into pieces.
In 2022, Google researchers Wei et al. proposed Chain-of-Thought (CoT) prompting, an approach that encourages LLMs to break down a complex “thought” (an LLM’s response) into intermediate steps by providing a few demonstrations to the LLM (few-shot learning). They found that CoT prompting boosted LLMs’ performance at complex arithmetic, commonsense, and symbolic reasoning tasks, all types of tasks resistant to the improvements that scaling laws granted to LLMs in other areas. Beyond this, CoT prompting eventually inspired even more capable “Tree-of-Thought” and “Graph-of-Thought” prompting. Let’s dig into how CoT works and how Wei et al. measured its success.
How Chain-of-Thought (CoT) Prompting Works
At its core, CoT prompting spurs reasoning in LLMs via decomposition. When we tackle a complicated enough math or logic question, we often can’t help but break the larger problem into a series of intermediate steps that help us arrive at a final answer.
Wei et al. figured out that large enough LLMs can do the same if we provide them with a few examples of how to do so. CoT can be done conveniently without readjusting any model weights (i.e., in-context learning). We’ll better see what CoT prompting looks like in a bit, but to give you a glimpse now, in the spirit of CoT prompting’s example-laden approach, here’s a side-by-side comparison of a standard input-output prompt and a CoT prompt:
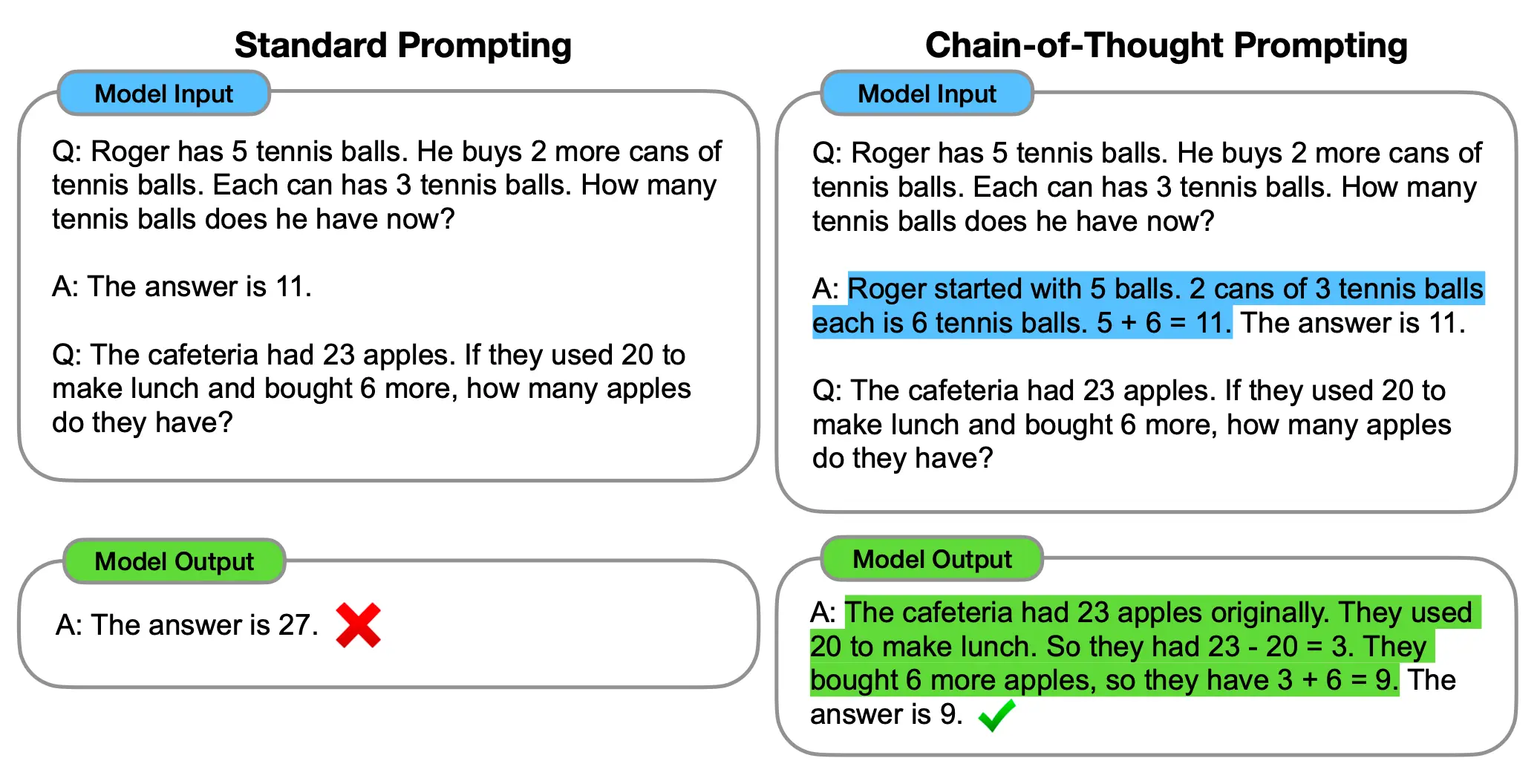
Image Source: Wei et al. (Standard Input-Output Prompt vs. CoT Prompt)
Image Source: Wei et al. (Standard Input-Output Prompt vs. CoT Prompt)
An added benefit of CoT prompting is that it provides us the opportunity to debug LLMs’ reasoning deficits intuitively. Since LLMs are asked to think one step at a time in CoT prompting, humans can readily see which step an LLM stumbles on (though we may still scratch our heads at why the black box model returned that erroneous step). We can then use this feedback to tweak the examples we feed an LLM, similar to a skilled teacher persistently altering examples for a confused student until one finally sinks in.
CoT, What is it Good For?
Though CoT prompting probably works well for many things, Wei et al. specifically tested CoT prompting’s prowess on arithmetic, commonsense, and symbolic reasoning tasks. First, let’s look at how CoT helped LLMs up their math game.
Grade School-Level Math Word Problems
To test CoT’s impact on LLMs’ arithmetic reasoning, Wei et al. used the following niche LLM benchmarks, all designed to test LLMs’ capacity to solve math word problems:
GSM8K (8.5K conceptually simple grade school math word problems)
SVAMP (1,000 unusually structured math word problems up to 4th grade-level difficulty)
ASDiv (2,305 diverse, elementary school-level math word problems)
AQuA (100k samples of algebraic word problem questions, answers, and intermediate rationales for those answers)
MAWPS (3,320 math word problems containing minimal lexical overlap with other benchmark problems)
For their baseline, Wei et al. used few-shot prompting, giving LLMs a few in-context examples of correct inputs and outputs (without the intermediary steps that CoT involves) before asking them for their final answers. CoT prompting is like few-shot prompting but with a key difference: when feeding LLMs examples, instead of only giving LLMs examples and their coinciding desired outputs (e.g., “The answer is 11.”), you show LLMs a series of steps that lead to a desired output (e.g., “Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11.”).
The majority of these questions were free-form, though some were multiple-choice. For each free-form question, Wei et al. manually created eight few-shot examples augmented with CoT and did the same for AQuA’s multiple-choice questions, but only with four few-shot examples. Below are a few samples of what the math problems and accompanying CoT prompts looked like (in addition to the commonsense and symbolic reasoning questions that we’ll get to later):

Image Source: Wei et al. (Highlighted portions are CoT augmentations to few-shot prompts. Standard few-shot prompt examples would be the same questions and answers minus the highlighted portions. Green = Math, Orange = Commonsense, Blue = Symbolic)
Image Source: Wei et al. (Highlighted portions are CoT augmentations to few-shot prompts. Standard few-shot prompt examples would be the same questions and answers minus the highlighted portions. Green = Math, Orange = Commonsense, Blue = Symbolic)
Results
With their handcrafted examples for each math word problem, Wei et al. tested different-sized models of five LLMs: GPT-3, LaMDA, PaLM, UL2 20B, and Codex. Across these models, CoT prompting minimally benefited mathematical reasoning until LLMs reached around 100B parameters, leading Wei et al. to consider CoT an emergent LLM ability.
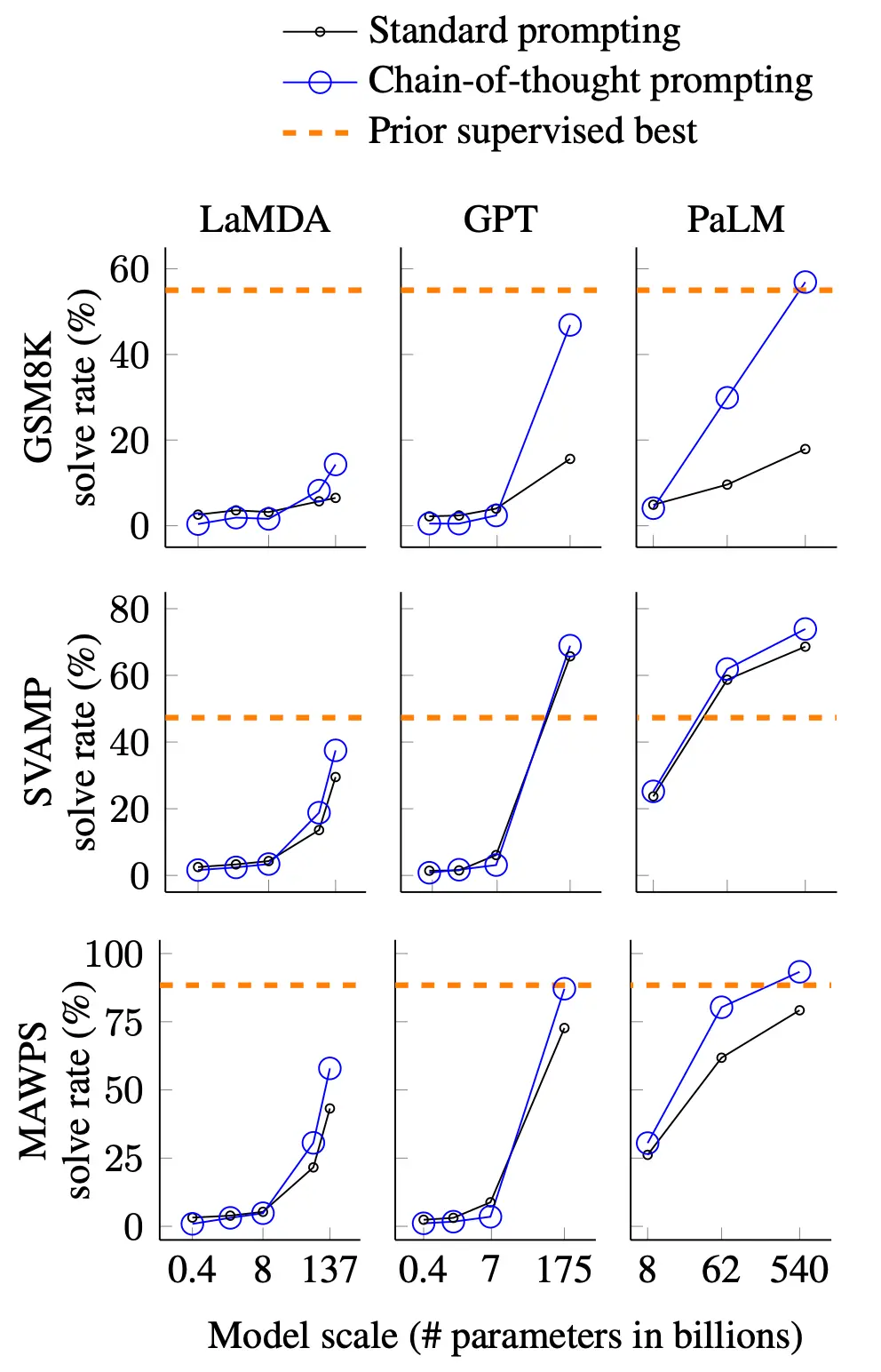
Image Source: Wei et al. (CoT prompts vs. standard prompts on math problem benchmarks. Note how CoT doesn’t offer a significant advantage over standard prompts until LLMs exceed ~ 100 billion parameters.)****
Image Source: Wei et al. (CoT prompts vs. standard prompts on math problem benchmarks. Note how CoT doesn’t offer a significant advantage over standard prompts until LLMs exceed ~ 100 billion parameters.)****
We et al. also found that the more complicated the math problem, the better CoT boosted LLMs’ ability to answer that problem, more than doubling, for example, GPT-3’s and PaLM’s performance on GSM8K (the benchmark that the baseline performed poorest on). Finally, CoT achieved state-of-the-art performance (SoA) on a GSM8K, SVAMP, and MAWPS, besting some models specifically finetuned on math word problems through sheer prompt engineering.
Commonsense Reasoning Problems
Most of the time, humans handle many problems involving interactions with humans and the physical world with ease; we simply don’t have to think too deeply about them. But this type of commonsense reasoning still routinely trips up disembodied LLMs. Because of this, Wei et al. thought that CoT prompting might elevate LLMs’ commonsense reasoning, testing their hypothesis on the following five benchmarks designed to test LLMs’ commonsense:
CommonsenseQA (CSQA) (12,247 semantically complex questions about world knowledge that humans often take for granted)
StrategyQA (2,780 multi-hop reasoning questions requiring implicit reasoning, decomposed steps for answering these questions, and paragraphs referencing evidence for such answers)
BIG-bench’s Date Understanding (369 multiple-choice questions requiring LLMs to infer dates from contexts)
BIG-bench’s Sports Understanding (986 multiple-choice questions about plausible and implausible sports scenarios requiring knowledge of the relationships between “sports, actions, and athletes”)
SayCan (101 questions that require mapping natural language instructions to a sequence of robot actions chosen from a discrete set)
For these commonsense reasoning tasks, Wei et al. employed a similar approach to engineering CoT prompts for the math questions, randomly picking questions and manually crafting CoTs for them that should help LLMs learn through step-by-step examples.
Results
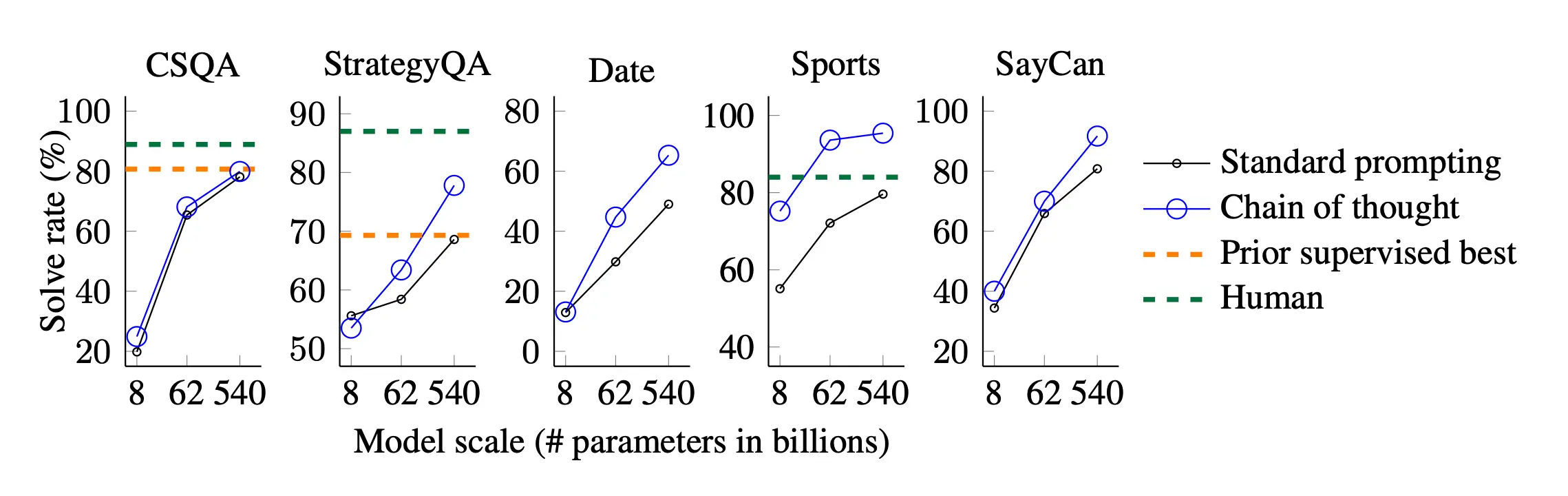
Image Source: Wei et al. (PaLM’s CoT prompt vs. standard prompt performance on commonsense reasoning benchmarks)
Image Source: Wei et al. (PaLM’s CoT prompt vs. standard prompt performance on commonsense reasoning benchmarks)
While the increase was minimal for CSQA, CoT lifted performance over baselines on all the above benchmarks, exceeding human performance on Sports Understanding (95.4% vs. 84%) and beating SoA on StrategyQA (75.6% vs. 69.4%), confirming CoT prompting’s utility toward diverse commonsense reasoning problems.
Symbolic Reasoning Problems
Traditionally, LLMs struggle at symbolic reasoning tasks, which has piqued some folks’ interest in neurosymbolic approaches as a remedy. But maybe CoT can lend a helping hand here, too? To check this, Wei et al. used two tasks:
Last Letter Concatenation (LLC): joining the last two letters of words of randomly generated names like this: “Amy Brown” → “yn”
Coin Flip (CF): answering whether a coin is heads up after reading a short description like, “A coin starts heads up. Phoebe flips it. Osvaldo doesn’t flip it. Is the coin still heads up?” → “No”
As with mathematical and commonsense reasoning tasks, Wei et al. again manually crafted few-shot CoT examples for the LLC and CF tasks. They also used in-domain and out-of-domain test sets, meaning some of their test questions contained the same number of examples and steps as the two-shot examples provided to the LLMs in the prompt, and some test questions had more than the two-shot examples provided during prompting (e.g., the CoT prompt contained examples with a two-word name, but the test question asked the LLM to concatenate the last letters of a four-word name).
Results
CoT prompting outperformed standard prompting on both symbolic tasks but performed exceptionally better than standard prompting on the out-of-domain tasks, which you can see below:
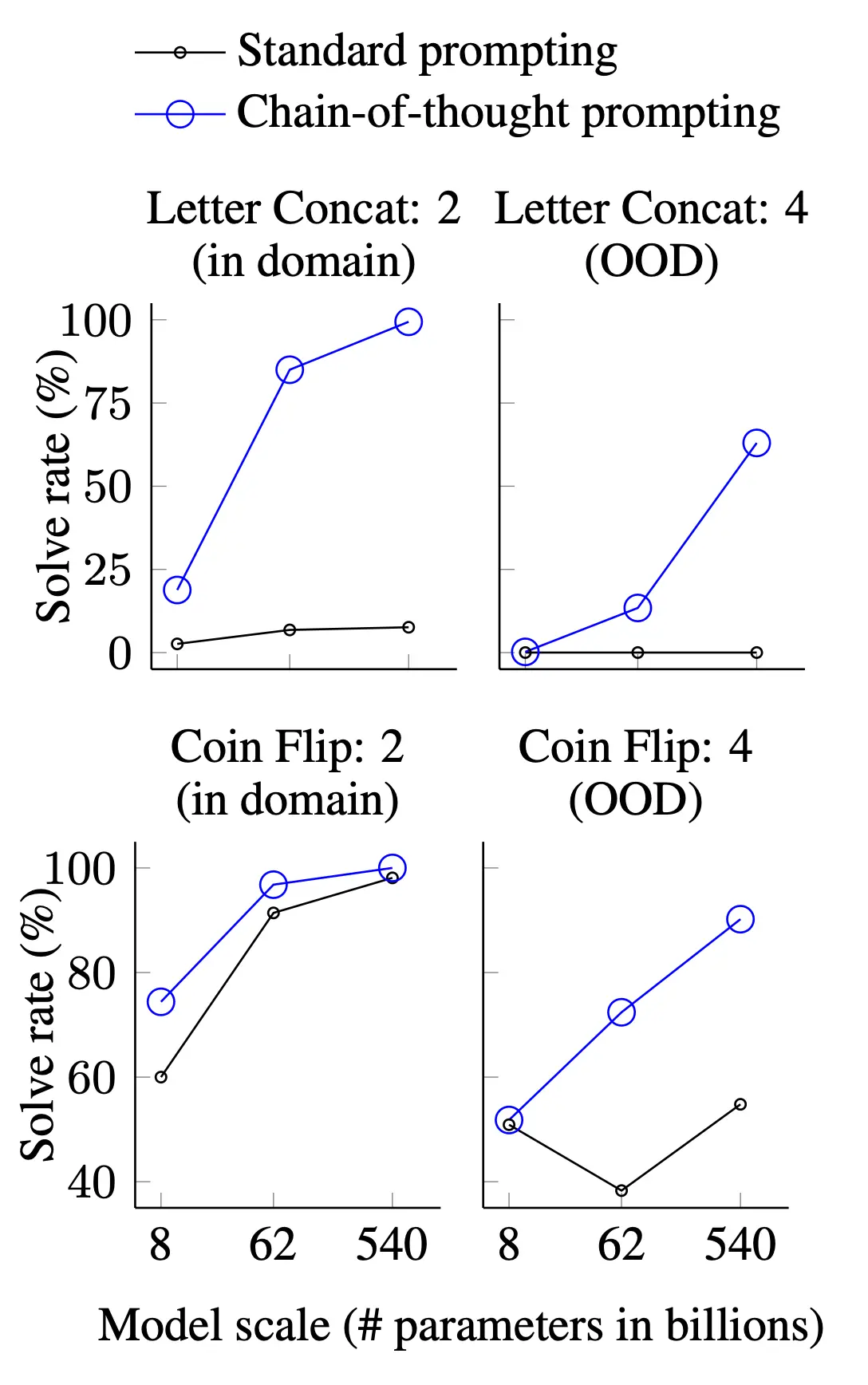
Image Source: Wei et al. (PaLM’s performance with and without CoT prompting on symbolic reasoning tasks)
Image Source: Wei et al. (PaLM’s performance with and without CoT prompting on symbolic reasoning tasks)
Why Does CoT Prompting Work So Well?
So, we can see that CoT increases LLMs reasoning abilities over several domains, but why does it confer benefits over vanilla few-shot prompting?
Wanting to test a few intuitive answers to this question, Wei et al. conducted three ablation studies which suggested that CoT’s prompting’s success at math word problems, for example, doesn’t stem from its ability to transform words into equations, nor from its increased computing power (allowing a chatbot to solve a problem in five intermediary steps, for example, allows it to process more tokens than constraining the chatbot to solve the same problem in a single step, meaning more compute) nor from the CoT prompt activating specific internal knowledge that LLMs gained during their pretraining.
Image Source: Wei et al. (Ablation studies suggest we can’t credit CoT prompts’ capacity to handle math problems to transforming words to equations, nor to increased compute, nor to strategically triggering LLMs’ training knowledge)
Image Source: Wei et al. (Ablation studies suggest we can’t credit CoT prompts’ capacity to handle math problems to transforming words to equations, nor to increased compute, nor to strategically triggering LLMs’ training knowledge)
Another aspect of CoT prompting’s success that Wei et al. wanted to rule out was the quality, number, and order of examples. Since standard CoT requires manually crafting examples for an LLM to learn from, you might attribute CoT’s performance to whoever generated the examples, the order the examples were presented, or the number of examples given. To rule this out, Wei et al. tested how the examples generated by several human annotators and how pre-generated examples from existing datasets (GSM8K already contains step-by-step explanations that Wei et al. used for this) affected LLMs’ performance on math word problems. They tested different orders of examples and different numbers of examples, too. Below, you’ll see non-trivial variance across example annotators, but CoT always solves more problems than standard prompting:
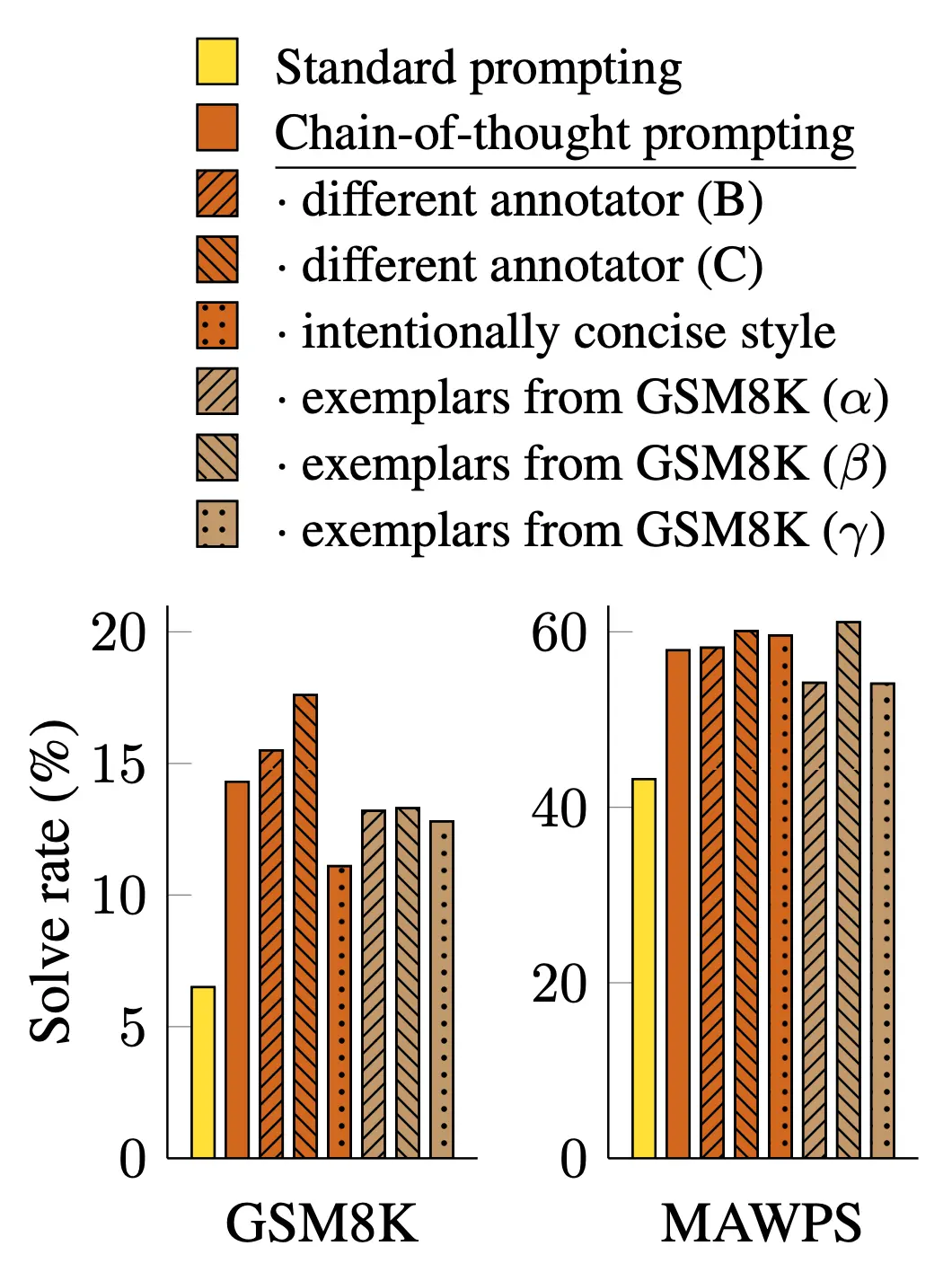
Image Source: Wei et al. (CoT prompts’ performances are influenced by their annotation style but tend to outdo standard prompting overall.)
Image Source: Wei et al. (CoT prompts’ performances are influenced by their annotation style but tend to outdo standard prompting overall.)
So, it seems that something else is at play here. Wei et al. believe it’s the power of expressing intermediate steps in natural language that helps LLMs articulate their “reasoning,” which, in turn, improves LLMs’ problem-solving capacity across several domains that we saw in their experiments (Wei et al. leave whether LLMs are “reasoning” as an open question). This is exciting because it suggests proper prompt engineering can make existing LLMs much more useful for certain tasks.
Chain-of-Thought Variants
Inspired by CoT prompting’s success, intuitive approach, and ease of implementation, many folks have altered CoT along various lines since its release. Let’s glance at a few of these CoT derivatives before wrapping up.
Zero-Shot Chain-of-Thought
Kojima et al. made a "Zero-Shot CoT" (zero-CoT) prompt to avoid the nuisance of providing several examples for an LLM to learn from. Less effective but easier to implement than standard CoT, Zero-CoT simply appends “Let’s think step by step.” to prompts, encouraging LLMs towards more methodical intermediate step-taking.
Despite not specifying any examples, Zero-CoT significantly boosts LLMs’ performance on arithmetic, symbolic, and logical reasoning benchmarks over a zero-shot, input-output prompting baseline. Using InstructGPT (Text-Davinci-002), Kojima et al. found that Zero-shot CoT, for example, went from 17.7% to 78.7% accuracy on the math problem benchmark MultiArith and elevated accuracy on the GSM8K benchmark from 10.4% to 40.7%, a huge jump for such a simple tweak. You can see below how much easier it is to write Zero-CoT compared to standard CoT prompts:

Image Source: Kojima et al. (Examples of Few-shot, Few-shot-CoT, Zero-shot, and Zero-shot-CoT prompts and outputs)
Image Source: Kojima et al. (Examples of Few-shot, Few-shot-CoT, Zero-shot, and Zero-shot-CoT prompts and outputs)
Automatic Chain-of-Thought
Automatic Chain-of-Thought (Auto-CoT) combines the convenience of zero-shot CoT and the superior performance of the original CoT’s manually crafted examples by using Zero-CoT to ask an LLM to create a set of question-answer demonstrations to be later used as CoT prompts. The Auto-CoT framework then clusters these LLM-generated CoT prompts to ensure a diverse sampling of question-answer examples, which are then used in the same manner as manual CoT prompting. Zhang et al. found that Auto-CoT matched or beat standard CoT on ten benchmarks.

Image Source: Zhang et al. (Auto-CoT’s framework. 1) LLM generates examples 2) cluster example 3) use a diverse set of examples as CoT prompt)
Image Source: Zhang et al. (Auto-CoT’s framework. 1) LLM generates examples 2) cluster example 3) use a diverse set of examples as CoT prompt)
Self Consistency with CoT
Wang et al. developed a different CoT approach. Since you can often take numerous paths to arrive at an answer to a math problem, for example, why don’t we ask an LLM to create several reasoning paths? CoT with self-consistency involves launching several diverse CoT threads, noting their outputs, and then considering the majority vote of these outputs as the most viable result. This approach improved over standard CoT prompting on multiple mathematic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%), and ARC-challenge (+3.9%).
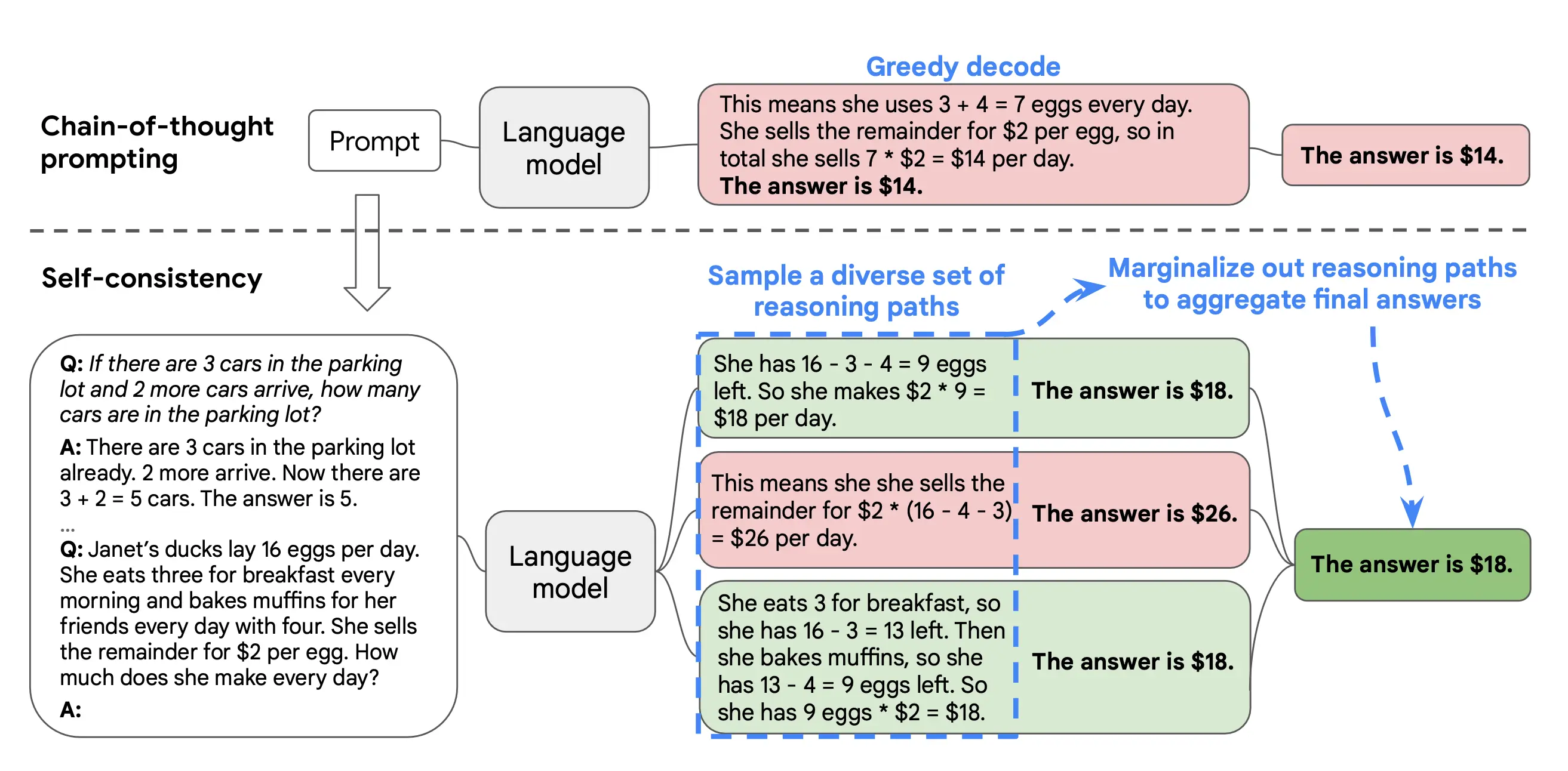
Image Source: Wang et al. (CoT with self-consistency framework)
Image Source: Wang et al. (CoT with self-consistency framework)
Unlocked Potential
Prompt engineering techniques like CoT prompting show us that LLMs still hold massive untapped potential that we can continue to excavate by experimenting with different prompting techniques. Some of these techniques, like CoT prompting, dovetail nicely with how humans tackle certain problems. For example, a diverse set of step-by-step examples demonstrating some arithmetic concept does wonders for our understanding.
Perhaps because of how intuitive CoT’s decomposition approach is to us, CoT has spawned many offshoots and, by merging it with some traditional data structures, has been extended into more sophisticated and powerful prompting approaches like Tree-of-Thought and Graph-of-Thought. We’ll go over both of these in upcoming articles, but CoT remains a simple, effective building block prompting strategy that significantly enhances an LLM’s performance without any finetuning, so give it a try the next time you’re straining to get what you want out of an LLM.