A subfield of artificial intelligence focused on enabling machines to produce human-like text based on provided data or prompts. It bridges the gap between data analysis and human communication, transforming structured data into coherent, contextually relevant narratives.
At the heart of human communication is our ability to craft stories, convey messages, and generate language. Natural Language Generation (NLG) seeks to imbue machines with a similar capability, enabling them to produce coherent and contextually relevant text from structured data or prompts.
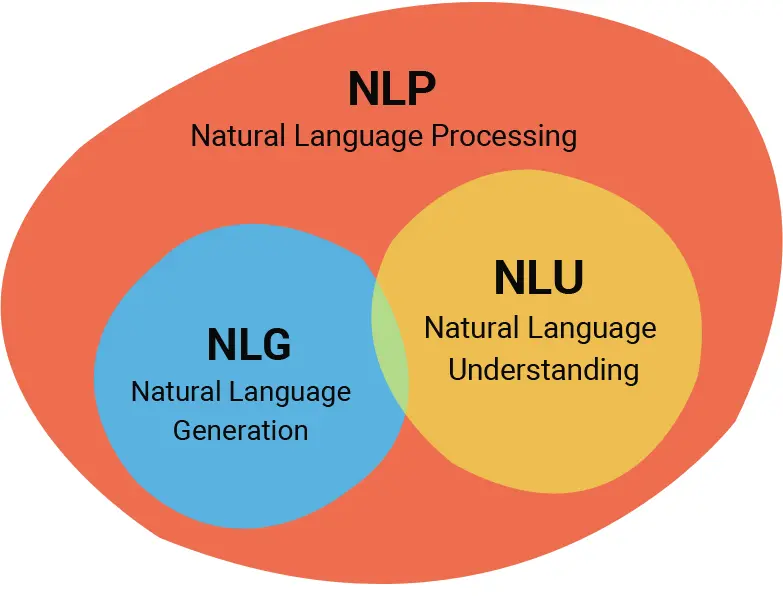
NLG and the NLP Spectrum: Natural Language Processing (NLP) is the overarching domain that deals with the interaction between computers and human language. Within this broad field, NLG stands as a complementary counterpart to Natural Language Understanding (NLU). While NLU is concerned with comprehending and interpreting human language, NLG focuses on the production aspect — creating meaningful sentences, paragraphs, or even entire narratives.
By aismartz, CC BY-SA 4.0
Understanding vs. Producing: Imagine having a conversation. When you listen and process information, you’re engaging in an activity analogous to NLU. When you reply, forming sentences to articulate your thoughts, you’re in the realm of NLG. Both are integral to full-fledged human-machine linguistic interaction.
The Goal: The point of all this research and innovation is to make computer-generated text that is indistinguishable from human-authored text in terms of grammar, structure, and overall readability. Potential applications range from summarizing datasets to composing creative fiction. However, significant research challenges remain to reach human parity across different genres and contexts.
Historical Context
Venturing into the annals of computational linguistics, the journey of NLG starts humbly but is rife with innovation.
Early NLG Systems: Initial forays into NLG often revolved around template-based systems. These systems had fixed textual structures where specific details were filled in based on the data provided. While effective for limited applications like generating weather reports, they lacked the dynamism and adaptability to handle complex, varied narratives.
Evolution Influences: As the digital era advanced, two factors played a pivotal role in NLG’s evolution:
Algorithms: Progress in machine learning and computational linguistics brought about advanced techniques that could generate language more fluidly. Rule-based methods evolved into probabilistic models and eventually to today’s neural network-driven approaches.
Data Availability: The digital age also ushered in an explosion of data. This abundance of information, particularly text, served as the training ground for sophisticated NLG models, refining their capabilities and versatility.
Mechanics of NLG
Data Collection and Processing
Behind every eloquent piece of machine-generated text is a meticulous process of gathering and preparing data. This data not only trains NLG models but also provides the raw material for them to generate language.
Types of Data Sources for NLG
Structured Data: This is data organized in a predefined manner, often in tables with rows and columns. For instance, a database of weather readings can be structured data, where each row represents a day’s readings and columns represent metrics like temperature, humidity, and wind speed. NLG can turn such data into readable weather reports.
Unstructured Data: This represents data that doesn’t have a fixed form. Think of news articles, books, or social media posts. While not organized in a rigid structure, this data is rich in linguistic patterns and can provide valuable insights for NLG models aiming to mimic human-like text generation.
Semi-structured Data: Somewhere in between, this data type might include things like XML files or JSON, where there’s some level of organization, but not as rigid as structured databases.
Pre-processing and Preparation
Data is rarely ready for immediate use in NLG. Several preparatory steps ensure it’s in the right shape:
Cleaning: Removing any inconsistencies or errors in the data, such as duplicate entries or missing values.
Tokenization: Breaking down text into smaller units (tokens), typically words or subwords. This step makes it easier for models to digest and learn from the data.
Normalization: Converting text into a standard form. This can involve making all letters lowercase, removing punctuation, or other transformations to ensure uniformity.
Sequencing: Especially for deep learning models, data might need to be organized into sequences or batches to train models effectively.
By diligently processing and preparing data, NLG systems are better equipped to produce text that is coherent, contextually relevant, and impressively human-like.
Template-Based Generation
In the initial days of NLG, before the rise of intricate machine learning models, template-based generation was the go-to method for producing machine-generated text. It was simple, predictable, and effective for specific tasks.
Fixed Structures with Variable Insertion Points
A template can be likened to a mold or a skeleton, where the broad structure of the content is pre-defined. Within this structure, there are designated slots or placeholders, which can be filled with variable data.
For instance, a weather report template might look like: “The weather in [CITY] on [DATE] is expected to be [CONDITION] with temperatures ranging from [LOW_TEMP] to [HIGH_TEMP].” Here, the terms in brackets represent variable insertion points that can be replaced with actual data values to generate diverse reports.
Benefits:
Predictability: The output is always structured and consistent, ensuring that the generated text always adheres to certain quality standards.
Efficiency: For domains with limited variability, templates can produce text rapidly without the computational overhead of more complex models.
Ease of Implementation: Setting up a template-based system requires less expertise and resources compared to training advanced neural networks.
Limitations:
Lack of Flexibility: The rigidity of templates means they’re ill-suited for tasks demanding diverse and dynamic content generation. Every deviation from the mold requires a new template.
Scalability Issues: As the number of scenarios or edge cases grows, maintaining a plethora of templates becomes cumbersome.
Overly Mechanical Output: The generated content can often sound robotic or overly formulaic, lacking the nuanced flair of human-like language.
While template-based generation might seem rudimentary compared to today’s advanced NLG models, it continues to hold value for specific applications where consistency and predictability are paramount.
Statistical and Rule-Based Methods
As the field of Natural Language Generation evolved, so did the methodologies. Stepping beyond templates, researchers explored the potential of leveraging statistics and rules to bring more flexibility and dynamism to the language generation process.
Using Patterns and Probabilities to Generate Language
Markov Chains: At the most basic level, Markov Chain models use the probability of one word following another in a given dataset to generate sentences. They rely on historical data to decide the likelihood of the next word in a sequence. While sometimes producing humorous or nonsensical outputs, they were a crucial step toward probabilistic language modeling.
N-gram Models: These models expand on the Markov Chain concept by considering the probabilities of sequences of ‘N’ words rather than just pairs. For instance, a trigram model (where N=3) calculates the probability of a word based on the previous two words, giving a more contextual approach to generation.
When Rules Dictate the Structure
Grammar Rules: Leveraging linguistic principles, rule-based systems employ a set of predefined grammar rules to generate language. For example, if the system wants to formulate a past tense sentence, it would adhere to the rules governing past tense verb conjugation in English.
Knowledge-based Systems: Going beyond mere grammar, these systems incorporate semantic and real-world knowledge. They might use ontologies or knowledge graphs, encoding relationships between entities and concepts to generate more coherent and contextually appropriate sentences.
Mixed Methods: Sometimes, the best results come from a combination of rule-based and statistical methods. These hybrid systems aim to get the flexibility and contextual understanding of statistical models with the structured correctness of rule-based approaches.
Benefits:
Flexibility with Structure: By employing rules, these methods can ensure certain linguistic structures or standards are maintained, while probabilistic methods add a layer of adaptability.
Transparency: Especially with rule-based methods, it’s clear why a certain piece of text is generated, making the process more interpretable compared to deep learning models.
Limitations:
Complexity and Maintenance: As languages evolve and use-cases expand, updating and maintaining an extensive set of rules can become challenging.
Less Fluidity: While more flexible than templates, these methods might still lack the fluidity and versatility of advanced neural models, especially when faced with novel contexts or intricate narratives.
The exploration of statistical and rule-based methods showcased the promise and potential in NLG. They paved the path for the neural revolution that would soon follow, blending structure with spontaneity.
Neural Language Models
The progression of NLG took a quantum leap with the advent of neural networks. By harnessing the power of deep learning, the language generation process has grown exponentially in terms of fluency, adaptability, and sophistication.
Introduction to Deep Learning in NLG:
Deep learning, a subset of machine learning, employs multi-layered neural networks to learn patterns and make decisions. In the context of NLG, these networks learn the intricate structures, semantics, and styles of language from vast quantities of text, enabling them to generate human-like content with remarkable proficiency.
Sequence-to-Sequence Models, Attention Mechanisms, and Transformers:
Sequence-to-Sequence (Seq2Seq) Models: These models revolutionized many NLP tasks, from translation to text summarization. They consist of an encoder that digests the input and a decoder that produces the output. For NLG, this could mean translating a structured data input into a coherent textual output.
Attention Mechanisms: A major breakthrough in Seq2Seq models was the introduction of attention. Rather than relying solely on the final state of the encoder to decode an output, attention allows the decoder to “focus” on different parts of the input, making the generation process more contextually aware and dynamic.
Transformers: Building upon the idea of attention, Transformers employ multiple attention mechanisms to process input data in parallel (as opposed to sequentially), leading to faster and more efficient learning. They’ve become the backbone of modern NLG systems.
Popular Models Like GPT and Their Contribution:
GPT (Generative Pre-trained Transformer): Developed by OpenAI, GPT models have set multiple benchmarks in the world of NLG. Pre-trained on vast swathes of the internet, these models can generate text that’s often indistinguishable from human-written content. The various iterations, from GPT-2 to GPT-4, have showcased the rapid advancement and potential in neural-based NLG.
BERT, T5, and Others: While GPT is decoder-only, models like BERT (from Google) are encoder-only, trained to understand context from given text. There are also models like T5 (Text-to-Text Transfer Transformer) which treat every NLP task as a text-to-text problem. These models, while not solely for NLG, have components and principles that have influenced and improved the state-of-the-art in language generation.
The neural revolution in NLG has not only elevated the quality of generated text but also expanded the horizons of what’s possible. From drafting articles to scripting narratives, these models blur the lines between machine output and human creativity.
Applications of NLG
The magic of NLG is not confined to the labs and research papers; it’s manifesting in real-world applications, reshaping industries and offering unprecedented value.
Automated Report Generation (e.g., Weather, Finance)
Weather Reporting: Imagine getting tailored weather updates for your exact location, with predictions and insights generated in real-time. NLG systems, fed with meteorological data, can craft reports that are both precise and engaging.
Financial Summaries: Financial institutions deal with a deluge of data daily. From stock market fluctuations to company earnings, NLG tools distill these vast datasets into comprehensible financial reports, offering quick insights and overviews for stakeholders.
Content Creation for Marketing and SEO
Automated Article Drafting: While human creativity is irreplaceable, NLG can assist in drafting content, especially for data-driven pieces. Think sports recaps, real estate listings, or product descriptions.
SEO Optimization: Crafting content optimized for search engines requires a blend of relevance and keyword inclusion. NLG systems can generate or suggest edits to content, ensuring it aligns well with SEO strategies.
Creative Writing: Poetry, Stories, and Beyond
Poetry and Prose: Pushing the boundaries of what machines can achieve, there are NLG models that generate poetic verses or short stories. While they might not rival Shakespeare or Tolkien, they’re a testament to the versatility of these models.
Scriptwriting and Plot Generation: Emerging applications include crafting movie scripts or generating plot outlines. Some indie game developers and writers even use NLG tools for brainstorming or prototype storyboarding.
Assistive Technologies: Helping Users with Language Disabilities
Communication Augmentation: For individuals with conditions like aphasia, NLG can offer predictive text options, aiding them in constructing sentences and facilitating smoother communication.
Learning Aids: NLG can be integrated into platforms designed for people with dyslexia or other learning disorders. By transforming complex texts into simpler versions or offering explanations for challenging words, these systems make information more accessible.
The landscape of NLG applications is vast and ever-evolving. As the technology matures, we’ll likely witness its footprint expand, touching domains we’ve not even imagined yet.
Challenges in NLG
As promising and transformative as NLG has been, it’s not without hurdles. To harness its full potential and ensure its ethical application, it’s essential to address and navigate these challenges.
Achieving Coherence and Cohesion in Longer Texts
Maintaining Narrative Flow: While NLG can craft sentences and paragraphs with remarkable accuracy, ensuring that a longer piece, like an article or story, flows seamlessly remains challenging. The absence of a true “understanding” can sometimes lead to disjointed or contradicting sections.
Context Retention: In longer texts, the ability to recall and build upon previously mentioned details is vital. Neural models, despite their prowess, can sometimes lose track of past context, leading to inconsistencies.
Avoiding Repetitiveness and Ensuring Variability
Diverse Expressions: One common critique of NLG systems is their tendency to fall back on familiar patterns, leading to repetitive phrasings. This is especially noticeable in tasks that require multiple similar outputs.
Overfitting to Training Data: Models that are excessively trained on specific datasets can become “overfitted”. This means they might produce outputs that are too closely aligned with their training data, leading to a lack of versatility in responses.
Handling Biases and Ensuring Ethical Generation
Embedded Biases: Language models are trained on vast datasets sourced from the internet, inheriting its biases. This can lead to outputs that reinforce stereotypes or display prejudiced views.
Manipulative and Misleading Uses: The ability of NLG systems to produce seemingly genuine content can be exploited to spread misinformation or produce fake endorsements.
Ethical Content Generation: As NLG becomes a tool for journalism, content creation, and more, there arises a responsibility to ensure that the generated content adheres to ethical standards, is transparent about its origins, and respects intellectual property rights.
While the promise of NLG is vast, these challenges underscore the need for continuous research, rigorous testing, and mindful application. Tackling these hurdles not only enhances the capabilities of NLG systems but also ensures their alignment with societal values and norms.
Future of NLG
As we stand at the precipice of a new era in computing, NLG’s trajectory promises advancements that might once have been the stuff of science fiction.
Personalized Content Generation Tailored to Individual Users
Hyper-Personalized Narratives: Beyond just recommending a product or curating a playlist, future NLG systems might craft entire narratives or news summaries tailored to an individual’s tastes, interests, and even their current mood.
Education and Learning: Imagine personalized textbooks or learning materials adapted to a student’s pace, style, and level of understanding, making education more flexible and tailored than ever before.
Collaborative NLG: Humans and Machines Co-Authoring
Enhanced Creativity: Writers, journalists, or scriptwriters might co-author with NLG tools, using them to brainstorm ideas, draft sections, or even refine language. It’s less about replacement and more about amplification of human creativity.
Real-time Collaboration: Professionals in fields like law or medicine might collaborate in real-time with NLG systems to draft documents, analyze cases, or provide insights, streamlining processes and enhancing precision.
The Potential of Integrating Richer Multimodal Data
Beyond Text: Future NLG systems could integrate visual, auditory, or even tactile data. This means generating content based on a mix of text, images, sounds, and more, paving the way for richer and more immersive content experiences.
Augmented and Virtual Reality: As AR and VR technologies grow, NLG can play a pivotal role in crafting dynamic narratives or simulations based on multimodal inputs, reshaping entertainment, gaming, and training modules.
Conclusion
The rise of NLG in the digital era isn’t just a technological marvel; it’s a cultural shift. As machines get better at crafting language, our very interaction with information, stories, and even each other is being redefined.
But as we embrace this future, a clarion call must be made: Collaboration is key. Linguists can help refine the grasp of syntax and semantics, storytellers can ensure the soul of narratives remains intact, and ethicists can guide the moral compass of these tools.
In the union of code and language, of algorithms and narratives, lies a future rife with potential, challenges, and above all, stories yet to be told. It’s a future we must approach with curiosity, caution, and collaboration.