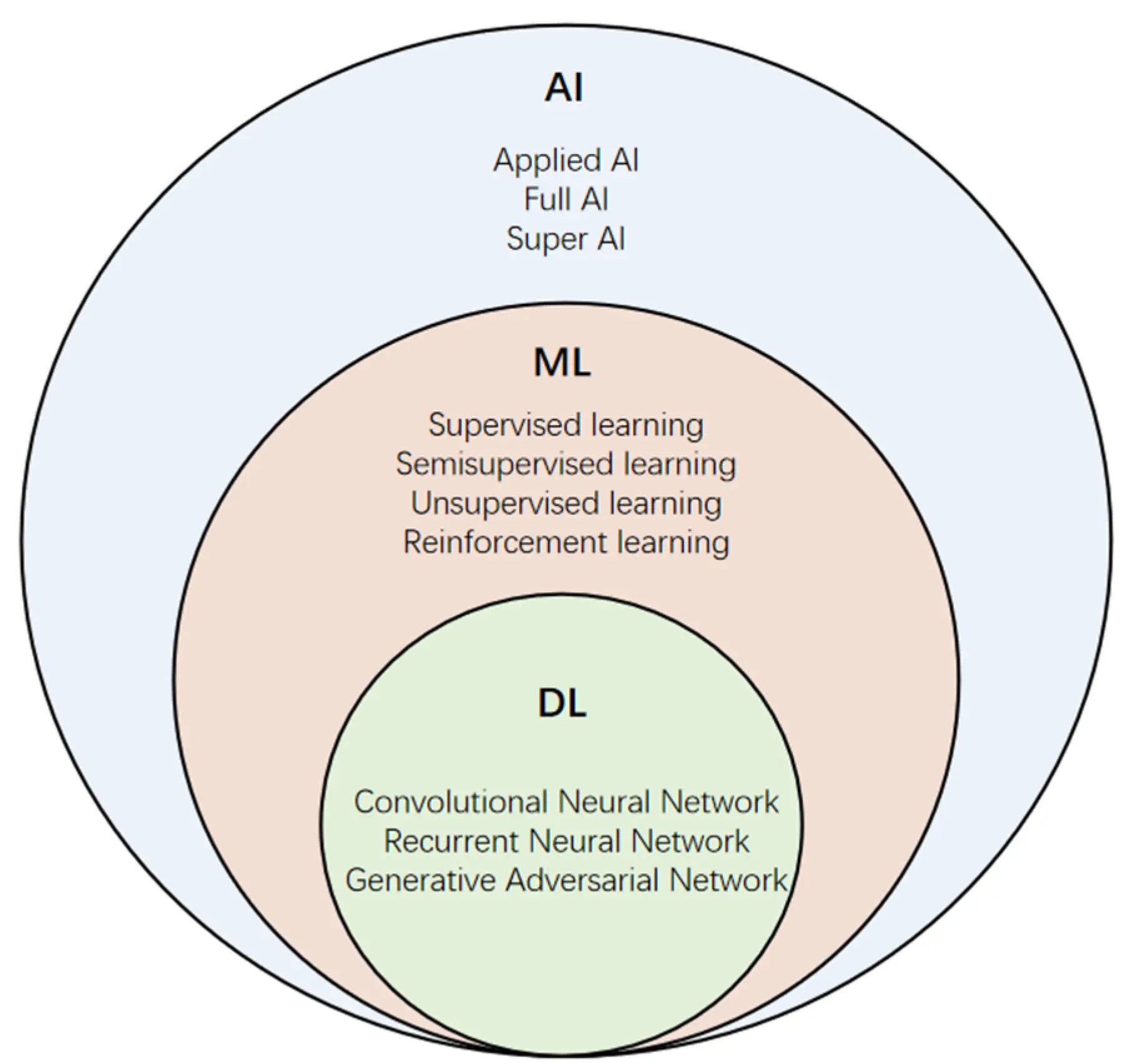
Deep learning is a subset of machine learning that utilizes multi-layered neural networks to analyze and derive patterns from complex data. It excels at tasks like image and speech recognition, largely due to its ability to process vast amounts of data and automatically learn features without explicit programming.
Deep learning, often mentioned in the same breath as artificial intelligence and machine learning, has taken the tech world by storm. But what exactly does it mean?
What is Deep Learning?
Deep learning is a subset of machine learning that focuses on algorithms inspired by the structure and function of the brain, specifically neural networks. These algorithms are designed to recognize patterns in vast amounts of data. The term “deep” in deep learning is not about any profound philosophical implication but refers to the multiple layers in these neural networks. Traditional neural networks might contain only 2-3 layers, while deep networks can have hundreds. The depth of these layers allows for more complexity.
Differentiating from Traditional Machine Learning
At its core, all machine learning involves teaching computers to learn from data so that they can make predictions or decisions without being explicitly programmed for the task. Traditional machine learning relies on feature engineering: experts need to tell the computer what kinds of things it should be looking for that might be indicative of, say, a cat being in a picture or a fraudulent credit card transaction. Deep learning, on the other hand, does away with this manual step. Given enough data and computational power, it determines on its own which features matter. It essentially automates the process of feature extraction.
The Significance of Deep Learning in Modern AI
Why has deep learning become such a buzzword? Its rise to prominence can be attributed to its incredible successes in areas where traditional machine learning models plateaued. Tasks such as image and speech recognition, which were considered highly challenging, have seen significant advancements thanks to deep learning. Technologies like virtual assistants (think Siri or Alexa), real-time language translation, and even self-driving cars owe much of their functionality to deep learning models. In essence, deep learning has brought us closer to the goal of creating machines that can simulate certain aspects of human intelligence.
By Wang, Tianming, Zhu Chen, Quanliang Shang, Cong Ma, Xiangyu Chen, and Enhua Xiao - Wang, Tianming, Zhu Chen, Quanliang Shang, Cong Ma, Xiangyu Chen, and Enhua Xiao. 2021. "A Promising and Challenging Approach: Radiologists’ Perspective on Deep Learning and Artificial Intelligence for Fighting COVID-19" Diagnostics 11, no. 10: 1924. https://doi.org/10.3390/diagnostics11101924, CC BY 4.0
Historical Context
Understanding the rise of deep learning requires a look back in time, to an era when the idea of mimicking the human brain was both revolutionary and controversial.
Origins of Neural Networks
The genesis of deep learning dates back to the mid-20th century with the idea of a “neural network.” Researchers like Warren McCulloch and Walter Pitts proposed models of artificial neurons in the 1940s, laying the foundation for what would become artificial neural networks. The idea was simple yet profound: could machines be designed to simulate the basic operations of the brain? The perceptron, introduced by Frank Rosenblatt in the late 1950s, was one of the first algorithms that tried to mimic how the human brain might work, focusing on pattern recognition.
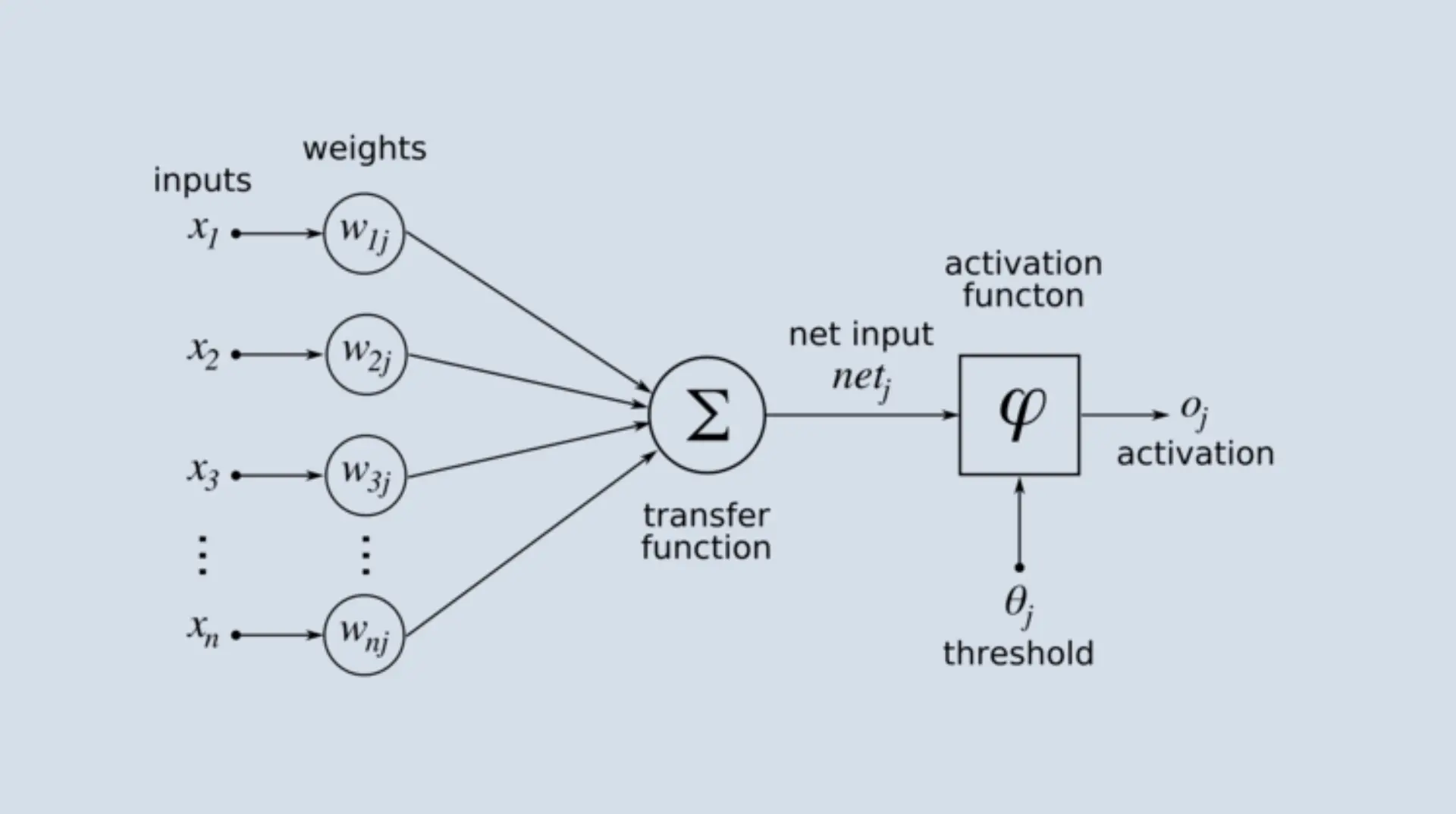
Diagram of Rosenblatt's perceptron.
The AI Winter and the Resurgence of Neural Networks
Despite early enthusiasm, by the late 1960s and early 1970s, neural networks faced skepticism due to their limitations, notably highlighted by Marvin Minsky and Seymour Papert in their book “Perceptrons.” This critique, coupled with the lack of computational power to effectively train large networks, led to reduced funding and interest in the field—a period often referred to as the “AI winter.”
However, as with most winters, spring followed. The 1980s and 1990s saw a resurgence of interest in neural networks, thanks to new algorithms, architectures, and techniques. Backpropagation, for instance, was a pivotal algorithm introduced that allowed neural networks to be trained more effectively.
Milestones that Shaped the Deep Learning Revolution
The 21st century heralded a new era for deep learning. Three primary catalysts propelled its rise:
Data Avalanche: The explosion of digital data—images, videos, text—provided the raw material that deep neural networks required to learn and refine their models.
Computational Power: Graphics processing units (GPUs) emerged as a boon for deep learning. Originally designed for video game graphics, their parallel processing capabilities made them ideal for training deep neural networks. (See also: AI Hardware)
Algorithmic Innovations: While data and hardware provided the fuel, algorithmic innovations like dropout, ReLU activation, and better weight initialization methods provided the spark, making the training of deep networks more feasible and efficient.
Key milestones include the success of deep nets in the ImageNet competition in 2012, the rise of models like AlexNet, and later architectures like CNNs and Transformers that have set new performance benchmarks in diverse tasks.
Fundamentals of Neural Networks
When it comes to deep learning, the central player is the neural network. These intricate architectures, inspired by our brain’s wiring, serve as the backbone for the most advanced machine learning models today.
Basic Architecture: Neurons, Weights, Biases, and Activations
Neural networks, at their simplest, are composed of layers of nodes or “neurons”. Each neuron is like a processing unit, taking in inputs, multiplying them by weights, summing them up, adding a bias, and then passing the result through an activation function. This activation function, such as the sigmoid or ReLU, introduces non-linearity, enabling the network to learn complex patterns.
Imagine a neuron as a decision-making box. It receives multiple signals, processes them, and produces an output signal. Now, stack many such boxes in layers, and you have a neural network!
Forward and Backpropagation
Training a neural network involves two main steps: forward propagation and backpropagation. In forward propagation, data flows from the input layer through the network’s layers to the output, generating a prediction. However, this prediction might be far from the truth, especially in early training stages.
This is where backpropagation comes in. It’s an optimization algorithm essential for adjusting the network. By comparing the network’s prediction to the actual truth, an error is calculated. This error is then propagated backward through the network, adjusting the weights using calculus, specifically the chain rule, to minimize the error.
Loss Functions and Optimization Techniques
The difference between the predicted and actual values is computed using a “loss function” (or cost function). This function gives a measure of how far off the network’s predictions are. Common loss functions include Mean Squared Error for regression tasks and Cross-Entropy for classification.
Optimization algorithms, like Gradient Descent or its variants (e.g., Adam or RMSprop), iteratively adjust the weights in the network to minimize this loss. Think of this as navigating a hilly terrain, trying to find the lowest point in the valley; that’s essentially what these algorithms do in the error landscape of the network.
Key Architectures and Models
Deep learning’s versatility is largely attributed to the wide variety of neural network architectures designed for specific tasks. These structures have been optimized over the years to excel in different domains, from vision to speech to sequential data.
Feedforward Neural Networks (FNN)
This is the simplest type of architecture. Data flows in one direction, from input to output, without looping back. While foundational, they’re often overshadowed by more complex architectures in many contemporary applications due to their limited capacity for capturing intricate patterns.
Convolutional Neural Networks (CNNs)
Tailored for image data, CNNs have revolutionized computer vision. They employ convolutional layers to scan input images with small, learnable filters, capturing spatial hierarchies. Pooling layers further downsample the data, reducing dimensions and computational needs. This design enables them to identify patterns like edges, shapes, and textures which can be combined to recognize intricate structures, from cat whiskers to human faces.
Recurrent Neural Networks (RNNs)
Designed for sequential data like time series or natural language, RNNs have a memory of sorts. They loop back, feeding previous outputs as inputs to the next step. This allows them to maintain a form of “state” or memory, making them suitable for tasks where temporal dynamics and context from earlier inputs are crucial.
However, vanilla RNNs face challenges like vanishing and exploding gradients, which limit their ability to remember long-term dependencies. This led to innovations like:
LSTM (Long Short-Term Memory): Designed with gates (input, forget, and output), LSTMs manage the flow of information, deciding what to retain or discard.
GRU (Gated Recurrent Unit): A simpler variant of LSTM with fewer gates but comparable performance for certain tasks.
Transformer Architectures
Transformers have taken the NLP world by storm. They sidestep recurrence, using self-attention mechanisms to weigh input elements differently, enabling the model to focus on more relevant parts of input data for a given task. BERT, GPT, and other state-of-the-art models are based on this architecture, setting benchmarks in numerous NLP tasks.
Hybrid Models and Others
In practice, many state-of-the-art models combine architectures. For instance, a CNN can process an image and feed its output into an RNN for video captioning. Additionally, architectures like autoencoders for unsupervised learning, or residual networks (ResNets) that ease training deep architectures, showcase the diverse strategies in deep learning.
Training Deep Models
Training deep learning models, while driven by foundational principles, comes with its set of intricacies. It’s an art as much as it’s science, involving the right mix of data, techniques, and intuition to ensure efficient learning while avoiding pitfalls.
Importance of Data in Deep Learning
Deep learning, often dubbed “data-hungry”, thrives on large datasets. The depth and complexity of these models demand vast amounts of data to capture subtle patterns, nuances, and variations.
Quantity: Large datasets help in painting a more comprehensive picture, allowing models to generalize well to unseen data.
Quality: Clean, well-labeled data is pivotal. Noisy or incorrect labels can mislead the model, leading to poor performance.
Strategies for Handling Limited Data
However, collecting extensive labeled data is challenging and sometimes impractical. In such scenarios, various techniques come to the rescue:
Data Augmentation: This involves slightly altering the original data to create new variants. For images, it might mean rotations, flips, or color changes. For audio, it could be changing pitch or speed.
Synthetic Data: Using algorithms or simulations to generate data that wasn’t originally collected but resembles real-world data. For instance, 3D engines can generate images for training vision models.
Transfer Learning: A powerful technique where a model trained on one task is fine-tuned for another related task. For instance, a model trained on general images can be fine-tuned with limited medical images to detect diseases.
Regularization Techniques
Deep models, with their vast number of parameters, can easily memorize training data, leading to overfitting. Regularization techniques prevent this, ensuring models generalize well:
Dropout: Randomly “dropping out” a subset of neurons during training. This ensures the model doesn’t rely excessively on any single neuron and promotes collaborative learning.
Early Stopping: Monitoring the model’s performance on a validation set and halting training once performance plateaus or worsens, preventing overfitting.
Weight Decay: A form of L2 regularization where a penalty is added to the loss function based on the magnitude of weights, discouraging overly complex models.
Challenges in Training
Training deep networks isn’t always smooth sailing:
Overfitting: When models perform well on training data but poorly on unseen data, having effectively memorized the training data.
Vanishing & Exploding Gradients: Deep models, especially RNNs, face this issue. As gradients are propagated backward, they can become extremely small (vanish) or large (explode), causing models to stall or diverge.
Applications of Deep Learning
The depth and versatility of deep learning have found resonance in diverse fields, often outperforming traditional techniques and opening up avenues previously deemed challenging.
Image Recognition and Computer Vision
One of the most celebrated domains of deep learning, computer vision, has undergone a renaissance with the advent of Convolutional Neural Networks (CNNs).
Object Detection: Whether it’s identifying items in pictures for social media platforms or spotting pedestrians in autonomous vehicles, deep learning algorithms efficiently categorize and locate objects.
Facial Recognition: From unlocking smartphones to security surveillance, algorithms can now detect and differentiate between human faces with remarkable accuracy.
Image Synthesis: Generative Adversarial Networks (GANs) can generate entirely new images, be it artwork or realistic human faces, blurring the line between real and artificial.
Natural Language Processing (NLP) and Translation
Deep learning has made significant strides in understanding and generating human language.
Sentiment Analysis: Companies use deep learning to gauge customer sentiment, parsing through reviews or social media mentions to determine how their products or services are perceived.
Machine Translation: Real-time translation tools, like those used in instant messaging, employ deep learning for quick and accurate language translation.
Summarization: Automatically generating concise summaries of long texts, making content more digestible for readers.
Speech Recognition and Synthesis
Interacting with devices using voice has become second nature, and deep learning is at the heart of this transformation.
Voice Assistants: Devices like Alexa, Siri, and Google Assistant rely on deep neural networks to understand and respond to user commands.
Text-to-Speech (TTS): Converting written text into spoken words, deep learning models generate lifelike speech, enhancing accessibility features and entertainment applications.
Speech-to-Text: Useful in transcribing services, these models convert spoken content into written form, aiding journalists, content creators, and professionals.
Medical Diagnostics and Drug Discovery
The medical field, with its wealth of data, is ripe for deep learning applications.
Medical Imaging: Detecting anomalies like tumors in X-rays, MRIs, or CT scans using deep learning can assist radiologists in diagnosis, often with higher accuracy and speed.
Drug Discovery: Predicting how different chemical compounds can act as potential drugs, deep learning accelerates the traditionally long drug discovery process.
Genomics: Parsing through vast genomic sequences, deep learning aids in understanding genetic factors behind diseases, paving the way for personalized medicine.
Interdisciplinary Connections
While rooted in computer science, deep learning has created ripples in various disciplines, forging unexpected connections and fostering synergistic growth.
Deep Learning in Neuroscience: Mirroring the Human Brain
The initial inspiration for artificial neural networks stems from biological neurons. This parallel has spurred dialogue and cross-pollination between machine learning and neuroscience.
Inspired Beginnings: Artificial neural networks, especially their basic units—neurons—are inspired by biological neurons. They emulate the signal transmission and activation mechanisms observed in the brain, albeit in a highly simplified manner.
Similarities in Learning: Both biological and artificial systems adjust their internal parameters (synaptic weights in the case of the brain) based on external stimuli or feedback to learn from experience.
Limitations & Divergences: While deep learning systems can perform specific tasks at or above human levels, they aren’t a perfect replica of the human brain. The brain’s dynamism, energy efficiency, and capacity for lifelong learning and adaptation outstrip current artificial models. Also, the ‘black-box’ nature of deep neural networks contrasts with the more interpretable processes of the human mind.
Feedback Loop: Insights from training artificial networks have piqued interest in neuroscientific investigations, with hypotheses about the brain being influenced by deep learning findings.
The Convergence of Physics and Deep Learning
The abstract nature of deep learning finds unexpected resonances with the world of physics, leading to enriched understandings and methodologies.
Optimization Landscapes: Training a neural network involves navigating high-dimensional optimization landscapes. Concepts from statistical physics, especially those around energy landscapes, have been employed to understand these training dynamics.
Quantum Neural Networks: Merging quantum mechanics and deep learning, researchers are exploring neural networks that operate on quantum principles. These networks might harness quantum parallelism, potentially revolutionizing computational capacities.
Physical Simulations: Deep learning models are aiding physicists in simulating complex systems, be it climatic patterns, quantum systems, or cosmic phenomena. These simulations, traditionally computationally expensive, are made more efficient using neural approximations.
Challenges and Controversies
Deep learning, while heralded for its capabilities, isn’t without its share of caveats. From inscrutable decision-making processes to ethical quandaries, the challenges are multifaceted.
Interpretability: The “Black Box” Dilemma
Deep learning’s power often comes at the cost of transparency. With complex models making decisions through intricate, non-linear transformations, understanding the “why” behind their outputs remains elusive.
Need for Explanation: In domains like healthcare or finance, it’s crucial not just to get accurate predictions but also to understand the underlying reasons. This interpretability can be vital for trust, especially when stakes are high.
Current Endeavors: Techniques like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) aim to shed light on model decisions, offering localized explanations for specific predictions.
Ethical Concerns
Deep learning’s reach and influence necessitate robust ethical considerations to ensure equitable and just outcomes.
Bias in Deep Learning: Models learn from data. If this data carries historical or societal biases, models can perpetuate or even amplify them. Instances like racial or gender biases in facial recognition systems spotlight this concern.
Surveillance: Enhanced object detection and face recognition techniques empower surveillance systems, leading to privacy infringements and potential misuse by authoritative entities.
Deepfakes: Deep learning can generate hyper-realistic but entirely fake content. These “deepfakes,” be it videos, audios, or images, pose threats to misinformation dissemination, privacy, and even geopolitical stability.
Environmental Concerns
The computational might deep learning demands has tangible environmental impacts.
Computational Costs: Training state-of-the-art models requires significant computational resources. These costs can be prohibitive for individual researchers, concentrating power among well-funded entities.
Carbon Footprint: The energy-intensive nature of deep learning computations has a real carbon footprint. For instance, training some advanced models can emit as much carbon as multiple car lifetimes.
Efficiency Drives: In response, there’s a push towards more efficient training methods, model pruning, and leveraging pre-trained models to reduce both computational and environmental costs.
The Future of Deep Learning
As we look beyond the present landscape of deep learning, we find a realm rife with promise, innovation, and integration. The canvas is vast, with technological advancements pushing boundaries and opening up new frontiers.
The Edge of Innovation: Architectures and Applications
Beyond the popular architectures of today lie potential designs and methodologies waiting to revolutionize deep learning.
Self-learning and Lifelong Learning Systems: Inspired by the human ability to learn continuously, future models might evolve to learn, adapt, and grow throughout their lifecycles, reducing the need for exhaustive retraining.
Neurosymbolic AI: Bridging the gap between neural networks and symbolic AI, there’s potential to combine the best of both worlds—deep learning’s data-driven nuances and symbolic AI’s rule-based clarity.
Augmented Reality and Virtual Reality: With AR and VR technologies maturing, deep learning could play a pivotal role in creating hyper-realistic virtual worlds, enhancing user experiences, and understanding user interactions in these virtual spaces.
Quantum Neural Networks: Tapping into Quantum Realms
Quantum computing, with its promise of unparalleled computational capacities, intertwines with deep learning, heralding potential breakthroughs.
Quantum Speed-up: Leveraging quantum mechanics, quantum neural networks might perform complex computations faster, potentially expediting tasks like optimization and sampling.
Hybrid Models: The initial forays might involve hybrid systems, where classical deep learning models interface with quantum processes, yielding benefits from both classical and quantum realms.
Convergence with Other AI Subfields
Deep learning, while a powerful tool in its own right, amplifies its potential when converged with other AI subfields.
Reinforcement Learning (RL): Deep Reinforcement Learning, where deep learning and RL converge, holds promise in domains like robotics, gaming, and autonomous vehicles. The combination could lead to machines that not only perceive the world but also act intelligently within it.
Generative Adversarial Networks (GANs) and Beyond: While GANs have garnered attention for their ability to generate realistic content, their principles of adversarial training might find broader applications, introducing novel ways to train and refine models.
Conclusion
Deep learning, an influential subset of machine learning, has undeniably played a pivotal role in the contemporary AI renaissance. Its capabilities, ranging from image recognition to natural language processing, have reshaped industries and catalyzed novel innovations. Yet, with this transformative power comes an inherent responsibility.
Balancing Promise with Prudence: The successes of deep learning, while commendable, should be contextualized with its limitations and challenges. As we harness its capabilities, a measured approach—one that understands its strengths and acknowledges its weaknesses—is indispensable.
Interdisciplinary Collaboration: The complexities of deep learning often intersect with disciplines outside computer science. Be it neuroscience, physics, or ethics, there’s an inherent value in fostering interdisciplinary dialogues. Such collaborations not only enrich the field but also ensure a more holistic evolution of the technology.
Responsibility and Ethics: The potential of deep learning is not just a technical consideration but a societal one. Its widespread applicability implies consequences that span beyond code and computation. Ensuring that its advancements are ethical, transparent, and equitable becomes paramount.
In the labyrinth of technological progress, the path forward for deep learning is as much about the algorithms and architectures as it is about the principles and values guiding its application. As we continue to explore and expand its horizons, let it be with a compass of responsibility, collaboration, and insight.