Unlike previous models (like RNNs and CNNs), Transformers can process extensive data sequences simultaneously for more nuanced analysis in text, speech, image recognition, and video editing. This parallel processing boosts efficiency and provides a better understanding of the underlying data than traditional sequential methods.
Transformers results from the 2017 paper "Attention Is All You Need". This paper introduces self-attention, an extension of the attention mechanism that enables Transformers to selectively focus on different parts of input sequences, essential for understanding the context and relationships within the data.
They excel at handling large datasets, learning from context, and processing information in parallel. These abilities make them highly effective across various applications, from advanced image recognition to automated language translation. For example, chatbots and art generators like Stable Diffusion and DALL-E, which create visual content from text, use Transformers as their architectural backbone.
Understanding Transformers
Consider the process of reading a complex novel. Instead of tackling one sentence at a time, you'd examine the entire page for a comprehensive understanding. This mirrors the operation of Transformers in machine learning—examining entire sequences in data input as a whole.
Unlike RNNs, GRUs, and LSTMs that process data sequentially (word by word or moment by moment), Transformers simultaneously assess the entire data sequence, providing a richer understanding of the context.
For example, translate the sentence:
“The bank is closed today.”
An RNN might confuse ”bank” for a riverbank or a financial institution, which may affect the translation's accuracy. In contrast, a Transformer processes the whole sentence simultaneously to detect that the token "bank" refers to a financial institution because the context depends on “closed”, leading to a more accurate translation.
RNNs can be slow with long sequences, struggling to retain distant information. Transformers, however, are faster and more efficient, making them superior for handling large datasets and complex tasks like language translation and video processing.
Key Components of Transformers
Transformers consist of several components that contribute to their efficacy, as seen in the architecture below from the original paper.
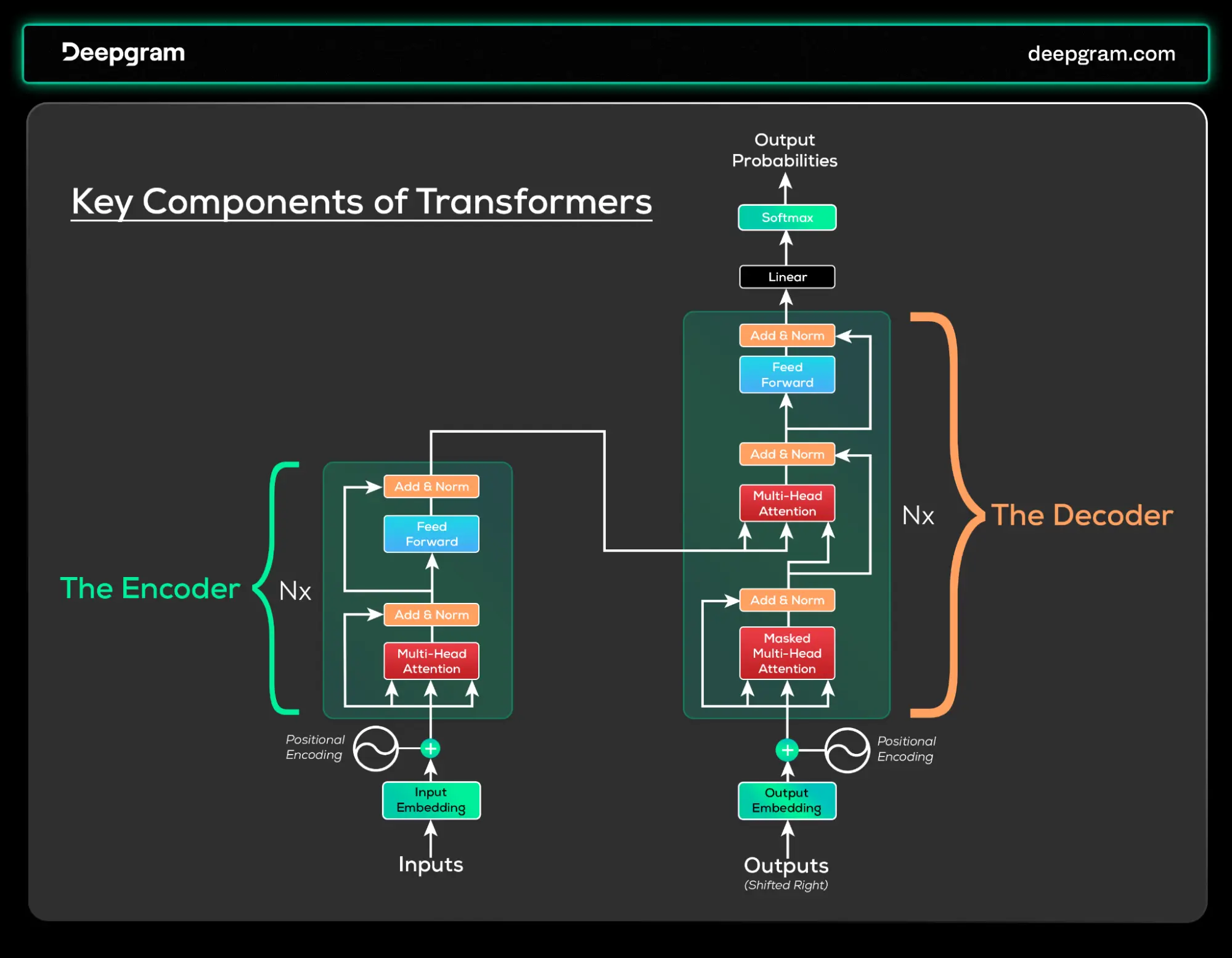
Fig.1. The transformer architecture. Source: https://arxiv.org/abs/1706.03762
Encoder and Decoder Architecture:
Transformers have an encoder-decoder structure—the encoder (on the left) processes input data (like a sentence in a translation task) and represents it as a rich, contextualized understanding. This representation holds information about each word and its relationships, capturing the context and nuances of the input data.
The decoder (on the right) then uses this representation to generate an output based on the ML task-. This architecture excels at generative tasks using rich, contextual understanding from the encoder.
Self-Attention Mechanism
At the core of Transformers lies the attention mechanism, which enables the model to selectively focus (to give “attention”) on parts of the input. This focus is critical to understanding the input context and connections between various elements.
In the encoder, self-attention involves analyzing each part of the input in relation to others, which helps it get a complete picture of the entire data. This process enables the encoder to capture both content and context effectively.
For the decoder, self-attention works differently. It starts with a series of inputs and utilizes information from the encoder and its previous outputs to make predictions. Similar to constructing a sentence, the decoder adds one word and then evaluates it continuously until a complete statement or phrase is formed, usually within a limit set by the user.
Multi-Head Attention
Building on the self-attention mechanism, the multi-head attention component in Transformers goes a step further. The encoder and decoder enable the model to simultaneously focus on different parts of the input from multiple perspectives. Instead of having a single "set of eyes" to look at the data, the Transformer has multiple, each providing a unique viewpoint.
In the encoder, multi-head attention dissects the input, with each 'head' focusing on different aspects of the data. For instance, in a sentence, one head might concentrate on the syntax, another might focus on semantic meaning, and another on contextual cues.
Similarly, multi-head attention enhances the model’s output accuracy in the decoder. Considering the encoder's output from multiple angles allows the decoder to make informed predictions about the next element in the sequence. Each head in the decoder pays attention to the input (via the encoder's representation) and what the decoder has already generated.
Input and Output Embeddings
In the Transformer model, input embeddings turn raw data into a high-dimensional vector space for the encoder. This makes it easier for the encoder to process single words or elements. The model learns these embeddings, which helps it understand different inputs.
Similarly, output embeddings in the decoder convert predictions into a vector format for generating human-readable text, which is also learned during training and essential for meaningful outputs. Input and output embeddings are both very important for making it easier for the Transformer to handle a wide range of tasks, ensuring that the results are correct and useful.
Positional Encoding
A unique challenge in Transformers is maintaining input data order since the model lacks built-in sequence understanding compared to RNNs. To overcome this, Transformers use positional encoding, assigning each element a position value based on its sequence order.
For example, in a sentence:
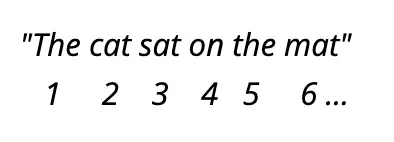
Each word gets a unique position value. This way, the model knows each part of the input and its position in the sequence. This setup ensures Transformers effectively handle tasks by capturing contextual relationships and individual data details, utilizing attention mechanisms for context, and Feedforward Neural Networks (FFNNs) for refining specific characteristics.
Feed-Forward Neural Networks (FFNN)
In the Transformer architecture, the encoder and decoder feature a key element called the FFNN. After passing through attention mechanisms, the FFNN in each layer independently processes each position in the input sequence. The FFNN structure involves two linear transformations with a nonlinear activation function in between, enabling it to learn intricate data patterns.
Layer Normalization and Residual Connections
Transformers use layer normalization and residual connections to improve training efficiency and effectiveness. Layer normalization stabilizes learning, and residual connections facilitate information flow across layers without loss.
Training Strategies and Regularization Techniques
Transformers use advanced training strategies like gradient clipping, learning rate scheduling, and regularization techniques like dropout. These methods prevent overfitting and contribute to the effective training of large models on vast datasets.
How Transformers Work: A Simplified Explanation
In a Transformer, the encoder starts by processing an input, like a sentence, using input embeddings and positional encoding to understand each word and its position. The self-attention mechanism then examines how words relate, creating a detailed context map.
This information goes to the decoder, which uses its self-attention and the encoder's insights to predict the next part of the output, like a translated sentence. The decoder’s output embeddings transform these predictions into the final output format.
Throughout, feed-forward neural networks and layer normalization ensure smooth processing. These components enable Transformers to efficiently translate complex inputs into coherent outputs, balancing detailed content with overall context.
Importance of Transformers
Transformers excel because of their parallel processing capabilities, allowing them to efficiently handle large datasets. Their bidirectional understanding of context enhances the accuracy of data interpretation. Their flexible architecture adapts well to tasks like language translation and image processing.
With features like multi-head attention and support for transfer learning, transformers are efficient with large datasets and valuable for various artificial intelligence applications.
Common Transformer Models
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT is an encoder-only model widely used for classification tasks, including sentiment analysis. Its strength lies in understanding the context of a word in a sentence, making it effective for various NLP tasks.
GPT Series (Generative Pre-trained Transformer): OpenAI's GPT series, especially the GPT-4 LLM (large language model), is renowned for its text generation capabilities. As a decoder-only model, it excels in creating coherent and contextually relevant text, contributing significantly to advancements in language models.
T-5 (Text-to-Text Transfer Transformer): Featuring an encoder-decoder architecture, T-5 is versatile in handling various NLP tasks. It can understand and generate text, managing tasks in a text-to-text format, including applications like image translation.
ViT (Vision Transformer): Google's Vision Transformers (ViTs) are pivotal in computer vision, enhancing tasks like image classification and object detection. They represent a significant shift in how images are analyzed, applying Transformer techniques to visual data.
Whisper: Developed by OpenAI, Whisper is a model specifically designed for speech recognition and audio processing. It showcases Transformers' ability to accurately transcribe speech, a crucial development in audio analysis technology.
Applications of Transformers
Natural Language Processing (NLP) Tasks: In NLP, they are used for tasks like language translation, text summarization, and sentiment analysis, as seen in models like OpenAI's GPT series and Google's BERT.
Computer Vision (CV) Tasks: Transformers drive image classification and object detection advancements. They are key components of models like Google's Vision Transformers (ViTs), which significantly enhance image analysis capabilities.
Speech Recognition Tasks: For speech recognition and audio processing, models like OpenAI's Whisper demonstrate Transformers' effectiveness in accurately transcribing speech.
Forecasting Tasks: In predictive analytics, Transformers aid in forecasting for finance and weather prediction. They also play a role in improving recommender systems and enriching user experiences on streaming platforms such as Netflix and Amazon.
The diverse applications of Transformers in handling complex data highlight their critical role in the evolution of AI technology.
Limitations of Transformers
Require Large Datasets: Transformers require large training datasets to produce good results, which can be impractical when data is limited.
Compute-Intensive Architecture: Their complex architecture demands significant computational power and energy, posing challenges in resource-constrained environments.
Training Data Bias: Bias in training data can also be a concern, as it may be reflected in the model's outputs.
Not Efficient for Simple Tasks: While versatile, Transformers aren't always the most efficient for simpler tasks, and their decision-making process can lack transparency, particularly in critical areas like healthcare.
As a result of these issues, continuous research is required to improve Transformer efficiency and ethical use.
Future Prospects and Innovations
Current research on AI Transformers is focused on bringing new advancements across various sectors.
Precise Treatment Diagnosis and Planning: We can expect more precise disease detection and analysis tools in healthcare.
More Advanced in Conversational AI: For language and communication, Transformers are likely to advance further in accurate translation and understanding, breaking down language barriers more effectively.
Better Creative AI Tools: In creative fields, the use of AI for generating artistic and design content is anticipated to grow.
Quantum Computing and Transformers: Combining Transformers with quantum computing is a promising area that could unlock even faster data processing capabilities.