HellaSwag: Understanding the LLM Benchmark for Commonsense Reasoning
Brad Nikkel

In the first part of this series on Hugging Face’s automated large language model (LLM) benchmarks, we explored how the AI2 Reasoning Challenge (ARC) measures a basic but vital LLM requirement—the ability to answer our questions.
But there’s a lot wrapped up in answering questions in a manner satisfying to us humans. We’d like LLMs, for example, to share humans’ notions of the physical world—the ones we usually take for granted. The next benchmark, HellaSwag, attempts to tackle this by evaluating common-sense reasoning in LLMs.
Benchmarking Commonsense Reasoning: HellaSwag
HellaSwag is a ridiculously cumbersome acronym for Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations. In 2019, Zellers et al. designed the HellaSwag dataset to test commonsense natural language inference (NLI) about physical situations.
When HellaSwag was released, SOA models like BERT had poor commonsense reasoning. To reveal this LLM shortcoming, Zellers et al. employed “Adversarial Filtering” (AF), a process that generates deceptive, challenging incorrect answers for a multi-choice test setting. These tricky, incorrect answers are dubbed “adversarial endings.”
Each adversarial ending contains words and phrases you’d expect to see in the correct answer, but their conclusions violate common sense (about the physical world). As a result, adversarial endings are a breeze for humans but pose a real conundrum for LLMs that lean hard on probabilities to reason about language. So much so that when LLMs were offered ample training data and even when LLMs were allowed to train on the test set (typically a machine learning taboo because it leads to overfitting and, in turn, unfounded confidence in a model’s performance), they still failed to cross the 48% threshold (back in 2019), while humans scored 95.6%.
Now that you understand HellaSwag’s general approach, let’s get into the weeds a bit. First, let’s look at the questions. HellaSwag’s questions are segments of video captions (describing some event in the physical world). A video caption segment provides an initial context for an LLM. Each context is then followed by four options for completing that context, with only one option being correct.
Interestingly, HellaSwag took humans out of the incorrect answer-generation loop due to humans’ tendency to unintentionally introduce subtle cues helpful to NLI models. Humans, however, re-entered the scene later, filtering out plausible machine-generated adversarial endings to ensure that the correct answer was unambiguous (to a human).
To improve upon their earlier SWAG dataset, Zellers et al. omitted all context completions easily detected by LLMs. Then, human crowd workers evaluated six context completion options (one correct and five machine-generated adversarial endings), retaining the top 70,000 most realistic-sounding adversarial endings. The result was a context completion dataset that’s challenging for LLMs but easy for human intuition.
Below are two examples of HellaSwag context and completion options. Take a moment to skim through the incorrect and correct (bolded) options; notice how the incorrect completion options contain words and phrases related to the context. And yet these incorrect completions, as a whole, jar against our commonsense notions of the world.
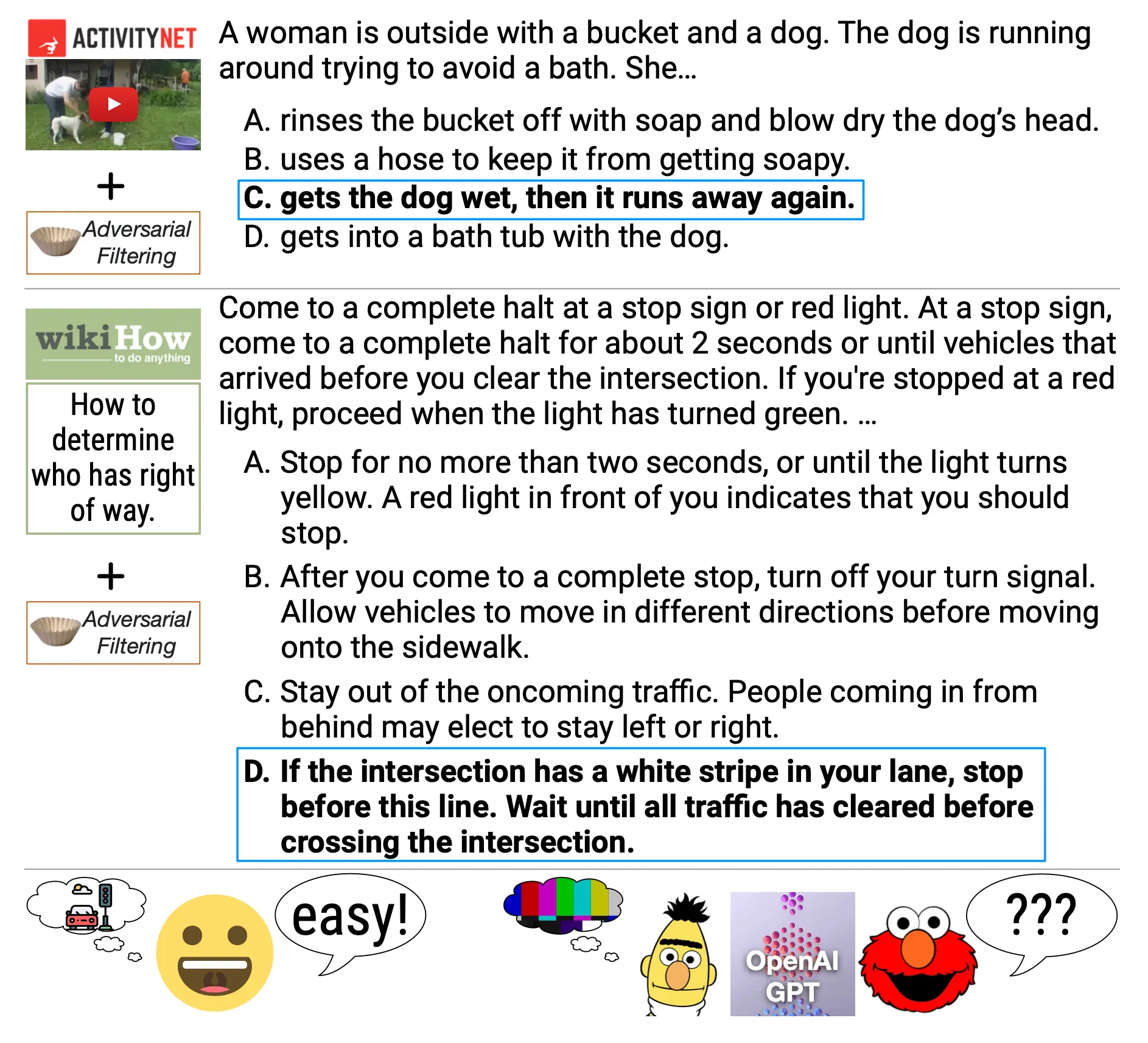
Image Source: Two HellaSwag contexts and their corresponding completion options (the correct completions are bolded).
Image Source: Two HellaSwag contexts and their corresponding completion options (the correct completions are bolded).
When humans and SOA models like OpenAI GPT, BERT-Base and BERT-Large, ESIM+ELMo, fastText, and LSTM initially completed HellaSwag, humans significantly outperformed all models. While human accuracy soared above 95%, these cutting-edge models (at that time) mustered accuracies below 50%.
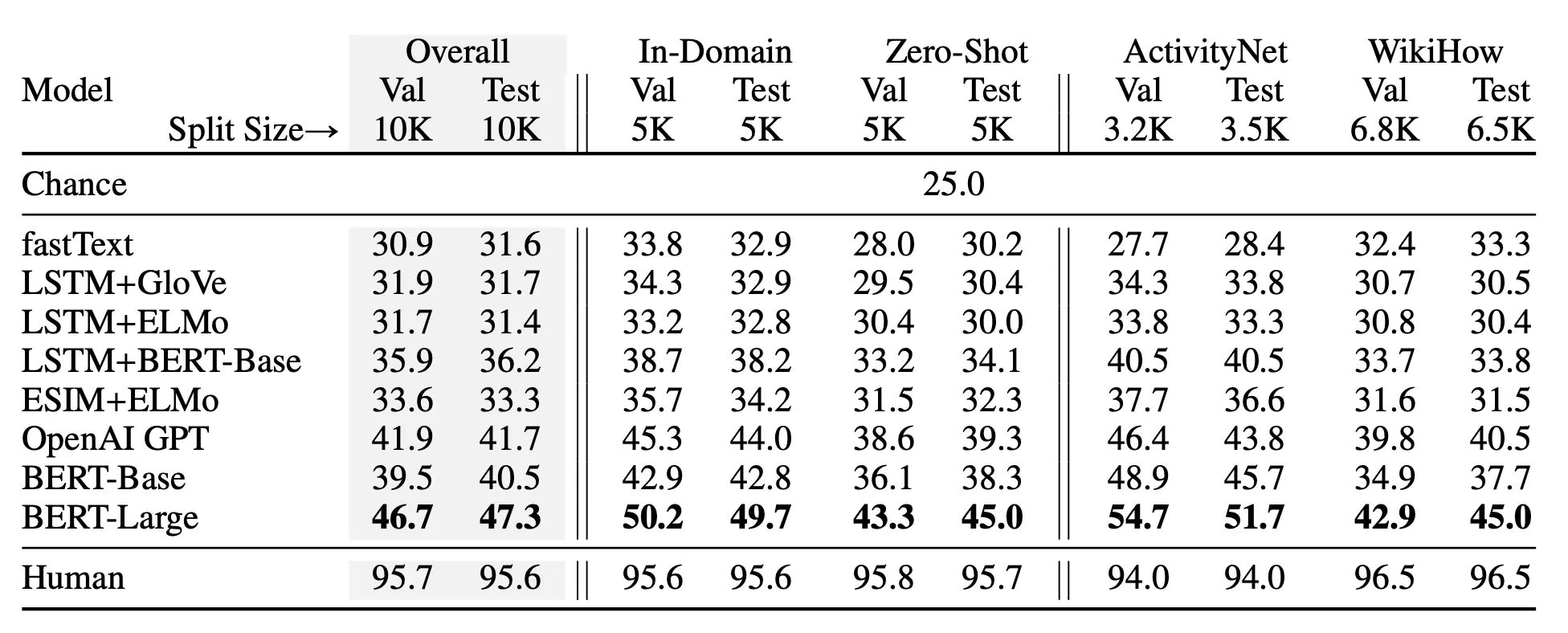
Image Source: Performance of initial models tested on HellaSwag. Notice the large gap between human and machine performance.
Image Source: Performance of initial models tested on HellaSwag. Notice the large gap between human and machine performance.
HellaSwag’s Contribution
Since HellaSwag was released in 2019, a non-trivial gap remains between humans, who score around 95%, and Falcon-40b, the open LLM leader on Hugging Face’s Leaderboard (as of July 4, 2023), which scores 85.3%. Closed-source LLMs, however, are now performing on par with humans, with GPT-4 scoring 95.3% with 10-shot reasoning.
Zeller et al., however, aren’t likely upset at this machine feat because their design approach is also a call to arms. They hoped that follow-on researchers would employ the best-known generator and discriminator models to create ever more adversarial datasets as LLMs gained human-level proficiency at HellaSwag; they wanted HellaSwag to push the field beyond static benchmarks toward evolving benchmarks.
You may notice some similarities between HellaSwag and the last benchmark we looked at (ARC). Both ARC’s and HellaSwag’s designers were unsatisfied with how existing benchmarks evaluated LLMs (in question-answering and common-sense reasoning, respectively) and thus set out to design more rigorous benchmarks. This is a common theme: some nagging dissatisfaction with current LLM performance (and their performance metrics) drives folks to create new, more challenging benchmarks.
The same holds for our next benchmark on Hugging Face’s Open LLM Leaderboard. In our next installment, we’ll explore how the designers of the Massive Multitask Language Understanding (MMLU) benchmark set out to measure how well LLMs actually understand various subjects.