Generative Adversarial Networks (GANs) are generative models developed by combining two neural network architectures: the generator and the discriminator. In this setup, both networks compete as “adversaries.” The generator's primary role is to create new data samples, and the discriminator's job is to assess their authenticity by distinguishing them from actual samples.
Introduction to Generative Adversarial Neural Networks (GANs)
Generative Adversarial Networks (GANs) are generative models developed by combining two neural network architectures: the generator and the discriminator. In this setup, both networks compete as “adversaries.” The generator's primary role is to create new data samples, and the discriminator's job is to assess their authenticity by distinguishing them from actual samples.
GANs typically use unsupervised learning techniques to learn from the data distribution without needing predefined labels. Through the adversarial relationship (competition) between the generator and discriminator, the model progressively improves itself to produce outputs that closely align with the expected distribution, creating new, realistic samples that are hard to tell from real samples.
Their ability to generate high-quality, realistic data has made GANs popular across various domains. They are widely used in artistic applications like style transfer and synthetic data creation.

History of GANs
The journey of GANs began as a solution to the need for high-dimensional, realistic, and diverse data samples. Traditional machine learning approaches often struggled with handling complex and varied real-world data, prompting GANs to emerge as a solution that expanded the possibilities of generative models. This overview offers a concise history, highlighting various endeavors by key contributors in the evolution of GANs.
2014: Origin of GANs
Goodfellow et al. (2014) proposed the GAN framework, introducing the generator (G) and discriminator (D) models to estimate generative models without relying on Markov chains or unrolled approximate inference networks, which were common in generative models of the time.
GANs gained attention for their ability to generate realistic images, sparking increased research interest in this area.
2015: Introduction of DCGAN
Radford et al. (2015) introduced Deep Convolutional Generative Adversarial Networks (DCGAN), which set new benchmarks for GAN architecture, focusing on generating realistic images through deep convolutional networks. This innovation improved stability and performance in image generation tasks. It introduced innovative concepts like image arithmetic, which enabled extracting features from specific latent spaces by conditioning images on others.
However, DCGAN faced limitations in the image resolution of the generated output, which led to the development of BigGANs by Brock et al. (2018). This solution generates high-resolution and realistic images. BigGAN is recognized as one of the largest and most computationally intensive GAN models to date.
2017: Progressive GAN
From NVIDIA, Karras et al. (2017) developed Progressive GAN, which scaled up images progressively, starting from smaller resolutions (like 4 x 4 or 16 x 16) and gradually increasing to larger sizes. This architecture improved the stability and detail of the image generated.
2018: Style GAN 1
In the Style GAN 1 model, each generator is conceptualized as a distinct style, with each style influencing effects at specific scales, such as coarse (overall structure or layout), middle (facial expressions or patterns), and delicate (lightning and shading or shape of nose) styles.
The researchers achieved that by mapping images from the latent space, ‘z’, to the intermediate latent space, ‘w’, through a dedicated mapping network.
2019: Style GAN 2
StyleGAN 2 improved upon its predecessor by addressing artifacts like phase and water droplet-like artifacts to enhance image quality and realism. It became a state-of-the-art model in GANs compared to its predecessors.
There has been a great deal of improvement in the GAN model since 2014. Despite its transformative impact on generative modeling and image synthesis, ethical concerns have emerged due to issues like deepfake technology and intellectual property infringement, such as the notable case of Robbie Barrat using GANs for AI art.
These concerns continue, but the GAN model continues to play a crucial role within the broader field of artificial intelligence and remains an important generative technology.
The Architecture of GANs
At the heart of the GAN framework is adversarial learning, which involves the generator and the discriminator networks that work with and against each other as part of the architecture.
This setup is a zero-sum game in game theory, where the success of one participant comes at the expense of the other. The networks work together by fitting the training data and learning from the data by adjusting the weights based on the errors to minimize the loss. Each network trains to work against the other. The goal is to reach a state of equilibrium where the discriminator cannot reliably distinguish between real and fake samples.
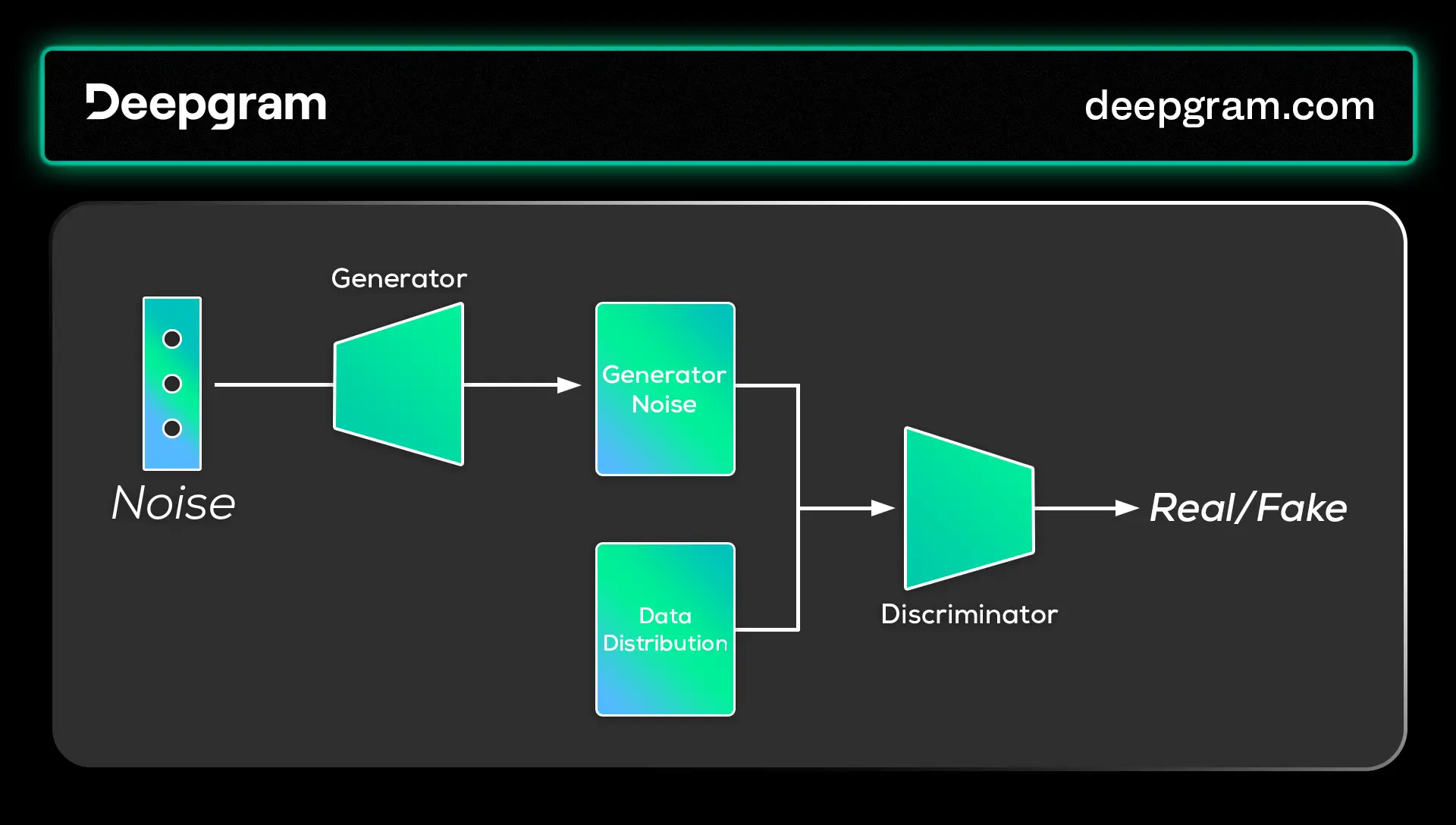
The generator initiates the process in GANs by producing artificial data from a random noise source. This data undergoes repeated improvements as the generator enhances its ability to mimic natural data distribution, resulting in outputs that progressively look more like actual data. Simultaneously, the discriminator assesses how genuine the generator's output appears, progressively learning to differentiate between real and generated data.
As the discriminator improves at identifying generated data, it pushes the generator to create increasingly realistic data. As the training process continues, at some point, the discriminator finds it challenging to distinguish between generated and real data.
The role of the generator
The generator initializes by generating synthetic data from random noise. This initial data is often far from the desired output but serves as a starting point for training the network. The generator then observes the real data distribution and adjusts its outputs accordingly. This objective is to generate data that closely resembles the real data so that the discriminator cannot tell the difference. The training process (adjusting the weights to minimize the error) is progressive, with the generator learning from each interaction with the discriminator.
The role of the discriminator
The role of the discriminator in the GAN architecture is to evaluate the authenticity of the data produced by the generator. It does this by distinguishing between actual data and the synthetic data created by the generator.
The discriminator fits the training data and learns to discern the differences between real and synthetic data from the generator. The objective of the discriminator is to assign high probabilities to real data points and low probabilities to synthetic points. Over time, the discriminator's ability to distinguish between real and synthetic data becomes more refined, providing a moving target for the generator to improve against.
In this context, it estimates the probability P(Y | X = x) that a given point is real, adjusting probabilities to assign a value of 1 for real examples and 0 for fake data points.
How GANs Learn: Training and Backpropagation
This learning process for GANs involves adversarial optimization of both the generator and discriminator. In other words, the objective of this process is to find a global optimum for the loss functions of both networks. This optimization achieves a state where the generator effectively reproduces the real data distribution.
The generator seeks to minimize its loss function, which is typically a measure of how easily the discriminator can identify its outputs as fake. Conversely, the discriminator aims to maximize its loss function, reflecting its ability to identify real and generated data correctly.
The generator's loss function
Here is the mathematical representation of the generator’s loss function:
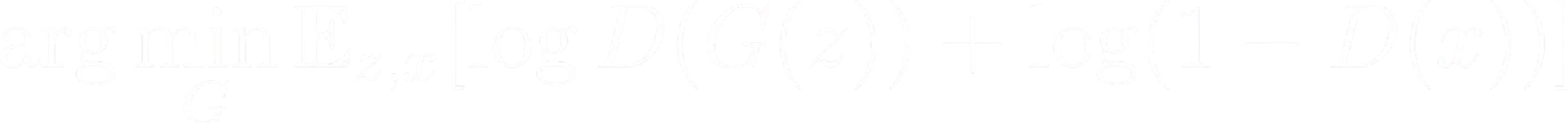
E denotes the expectation over the latent space (z) and the real data distribution (x).
The goal is to minimize the combination of two log-probability terms:
log(D(G(z)) represents the log probability that the discriminator (D) classifies the generated data as real.
log(1 - D(x)) represents the log probability that the discriminator correctly identifies real data as real.
The discriminator's loss function
Here is the mathematical representation of the discriminator’s loss function:
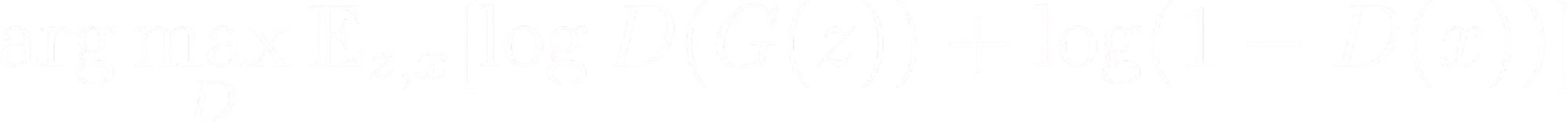
The function consists of two terms:
log(D(G(z)) which measures the probability the discriminator assigns to the generated data, aiming to maximize it.
The second term, log(1 - D(x)) evaluates the probability assigned by the discriminator to real data, striving to minimize it.
The overall aim is to find the optimal parameters for the generator that make the generated data indistinguishable from real data.
Unified training objective
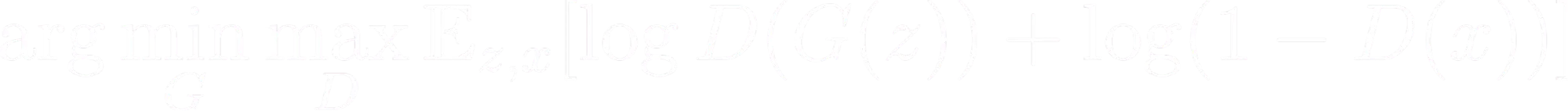
Combining the loss functions of each network, the unified training objective formula shows the essence of the entire training process. It emphasizes minimizing the generator's loss and maximizing the discriminator's loss, which brings both networks to an optimum point.
Backpropagation in GANs
Backpropagation in the network calculates the gradients of the loss functions, enabling the model to adjust its parameters and progressively improve performance. Typically, it involves adjusting errors backwards through the network, which helps refine both the generator and discriminator networks by minimizing their losses.
Evaluating GAN Performance
Evaluating the performance of GANs is more complex than assessing traditional machine learning models. You assess generative models using a combination of metrics that address different aspects of the generated output. Some metrics, like the Inception Score (IS), Frechet Inception Distance (FID), Human Evaluation, Precision, Recall, and F1-score, are combined to evaluate GAN performance based on the task it is used for.
Generally, these metrics evaluate different aspects of performance, such as image quality, diversity, similarity to real data distribution, and the ability to deceive a discriminator. The ultimate goal is to ensure that the generator produces high-quality, diverse, and realistic samples.
GANs in Action: Applications in Computer Vision
GANs come to life in computer vision with transformative applications ranging from image synthesis to object detection. Here are a few applications of GANs.
Image generation and enhancement
Models like StyleGAN, BigGAN, and other conditioned GANs have demonstrated great proficiency in generating realistic, high-resolution images or sketches. Their ability to capture fine details in images and produce diverse outputs makes them useful for various tasks, from artistic image creation to generating synthetic datasets for training ML models.
Data augmentation for machine learning
Data augmentation improves model performance in computer vision tasks and ML by diversifying the training dataset. When realistic variations of existing datasets are created with GANs for a computer vision task, it can enhance the robustness and generalization strength of the model, reducing the chances of overfitting. This is particularly valuable in fields where data is limited and challenging to collect.
Real-world examples and case studies
CycleGAN facilitates the translation of images in medical imaging across different modalities, aiding in diagnostic tasks or voice conversion. GANs are also used for image captioning or video synthesis, allowing the generation of descriptive captions for images and the creation of lifelike video sequences. These technologies have found significant use in virtual environments and simulations, among other applications.
Overcoming the Challenges in GANs
Despite their numerous applications and advancements, GANs face several challenges.
Stability and convergence issues
When training GANs, stability and convergence issues (the adversarial networks have difficulties reaching a stable and desired state) are usually a concern. Techniques like spectral normalization and progressive growing have stabilised the training process and addressed these issues. Different optimization techniques (like utilizing different learning rates for the generator and discriminator) can contribute to more stable and reliable training.
Mode collapse and diversity
Mode collapse occurs when a GAN fails to capture the full variability of the training data, leading to repetitive or limited outputs. Addressing this challenge involves incorporating minibatch discrimination or consistency regularization to make the generated samples more consistent. Using progressive growing and conditional GANs has proven helpful in ensuring the generated samples are varied and look real. It helps avoid generator mode collapse.
Ethical considerations and misuse prevention
Concerns about GAN technology, especially in making Deepfakes, have been seen within the research community and mainstream media. Efforts are underway to develop better methods for detecting Deepfakes and making AI more transparent. Responsible AI efforts and ethical guidelines are committed to reducing the potential harms of GAN misuse, like spreading misinformation and privacy breaches.
The Future of GANs: Beyond Image Generation
GANs have come a long way with lots of improvements, giving us different versions like Wasserstein GAN, which helps with stability and reduces problems like mode collapse; conditional GAN, which is task-specific and CycleGAN (great for speech or audio conversions); SpecGAN, WaveGAN, and GANsynth, which can be used to generate spectrographs and audio, among other innovations. Researchers are also exploring how GANs can work with new deep learning tools like Transformers, Physics-Informed Neural Networks, Large Language models, and Diffusion models.
GANs have moved beyond their initial image-related focus and are now used in tasks like text-to-image synthesis, image-to-image translation, time series, and semantic segmentation. These and many more advancements exemplify the ever-evolving research on GANs. Looking forward, the potential applications of GANs in computer vision and beyond are vast and diverse, making it an active and promising area of research and development.